
最近、「ディープラーニング」という言葉を耳にする機会は増えていますよね。ディープラーニング(深層学習)とは、人間が自然に行うタスクをコンピュータに学習させる機械学習の手法の一つで、近年開発が進む「自動運転」の技術もこの手法がカギを握っているとされています。では、「ベイズ理論」という言葉を知っている方はどのくらいいるでしょうか。確率論に基づいて統計的にデータを解釈する理論のことで、一見すると機械学習やディープラーニングとは関係ないようにも見えます。
そこで、今回は統計や機械学習、AIのブログ「作って遊ぶ機械学習。」を執筆し、ベイズ統計学・機械学習・ディープラーニングについての著書もお持ちの須山敦志さんに来ていただいて、ベイズ理論とディープラーニングの関係性や機械学習を学ぶうえでのポイントなどを解説してもらいました。誰もが聞いたことのある機械学習と統計手法であるベイズ理論がどのように関係しているのか、この記事を読めば一発で分かるようになるはずです。
ベイズ理論とディープラーニングのつながり
ーーベイズ理論に関するを本を出版することになったきっかけは何だったんでしょうか?

初めはイギリスで勉強したベイズ統計について、便利で素晴らしい方法論だということを知ってもらいたくて、2016年の1月ころからブログを書いていたんですね。
すると、始めて2ヶ月ぐらい、まだ記事も3~4記事だったころに講談社さんから「ベイズ推論による機械学習入門」の執筆に関するお話をいただきました。

「ブログそのままの、話しかけるような」テイストで理論を説明する本を書いてほしいと言われました。
そこで1冊出すと、2冊目、3冊目、といった形でお話がくるようになりましたね。
ーーベイズ理論・ディープラーニングの融合を本にした理由やモチベーションは何だったのでしょう?

ベイズ理論とディープラーニングそれぞれの専門家を見ていると、なんだか「仲が悪い」みたいな印象を受けがちなんですよ。
この「仲が悪い」という印象を持たれたくない、というのが本音です。
ベイズ理論とディープラーニングの両者には理論的なつながりがあって、ディープラーニングで使われている手法も実はかつてベイズ理論で使われていた分析手法だった、なんてこともよくあるわけです。
言っちゃえば、アイデアの出どころや発想が違うだけなんですよね。
この繋がりのすばらしさ、みたいなものを伝えていきたいですね。
ーー実際にベイズ理論とディープラーニングを組み合わせて機械学習モデルを作る場面も増えてきましたが、須山さんの周囲にもそういった方は多いですか?
実際、最近になってそういったことに取り組んでいる方は多くなってきていると感じますね。
ただ、自分はもともとイギリスでの仕事の経験もあるのですが、日本と比較すると格段にベイズ理論をディープラーニングに利用するアプローチに携わっている人に出会うことは多いですね。
もちろん、1年後2年後には現在の海外のようなフェーズに日本も入っていくと思いますよ。
ーーベイズ理論をディープラーニングに組み合わせることで表現力が上がり、自動的にアーキテクチャを構築してくれる、なんて話もありますよね?
もちろん、そういったアーキテクチャの構築手法もベイズ理論の応用の一つです。
ベイズ統計では課題やデータに合わせて適切なモデルを設計することが重要です。
モデリングの柔軟性の高さがベイズ統計の最大の強みです。
一方で、ディープラーニングでも、多くの場合データややりたいことに応じてネットワークアーキテクチャを設計する必要があります。
実は両者で本質的に行われていることは同じなんです。
ディープラーニングにおけるアーキテクチャの自動構築も、ノンパラメトリックベイズと呼ばれる手法を用いればベイズ理論の枠組みで考えることは十分可能です。
ーーディープラーニングにおける新しいアーキテクチャがすごいスピードで出現していますよね?
確かに、この進化の速さには僕も驚いています。
ただ、そういった場合、多くは技術の表面的な部分、いわゆる「皮」の部分の話題ばかりが先行してしまいがちです。
すごいスピードで広がっていく一つ一つの「皮」の技術に手を出しているとどうしても人間の脳みその限界にたどり着いてしまうので、そういった場合は一度我に返って中心にある「数学」に立ち返るのが良いと思いますね。

古くから使われている理論などに立ち返ることで、惑わされずに本質を見抜けるようになりますよ。
エンジニアがぶつかる「論文から実装への移行」という高い壁
ーー多くのエンジニアがぶつかる壁に「論文から実装への移行」があると思いますが、須山さん自身はどのようにこの壁を乗り越えましたか?

やはり、僕自身もその壁に関しては「完全にクリアした!」とはなっていませんね。
新しい理論などに触れる時は、僕自身も今までの経験値みたいなものはリセットされてしまいますし、そうあるべきだと思うんですよね。
「なんでも実装できるようになったぞ!」なんて人はいませんし、そんなことは今後も起こりえないでしょう。
ただ、一つアドバイスをするならば、非常に抽象的な存在である「数式」をいかにして実際に実装していくのか、という点を丁寧に確認していくことが大事だと思います。
例えば、数式中に出てくる変数がベクトルなのか、それとも行列なのか、次元はいくつなのか、といったような基本的なことをしっかりと確認するわけです。
そうやって具体的な実装を繰り返していくうちに、理解しづらかった抽象的な理論も理解できるようになっているはずです。
簡単なレベルの理論から始めて実装を繰り返しながらレベルアップする、という地道な流れしかないと思いますね。
あと、良い論文を見つけたら、理解に苦しんだとしても粘り強く向き合い続けることじゃないですか。
領域をあまり広げ過ぎず、一つの分野に対して深堀していく方が僕はオススメです。
なぜなら、その方が本質的に乗り越えるべき壁にぶつかりやすく、あの手この手でその壁を乗り越えようとする過程において強力なスキルが身に付いてくるからです。
そのようにして、その一分野を極めることが出来れば、その周辺領域も自然と理解できるようになるはずです。
ーーブログタイトル「作って遊ぶ機械学習。」からも分かるように、「楽しみながら」という点に重きを置いているように感じましたが?
そうですね、自分の中では結構重要視しているんですけど、たまに読者さんから「ガチガチの理論派すぎて全然楽しめてないのでは?」というお声も頂きます。
ただ、僕自身としてはこの裏に一つメッセージを設定しているんです。
実は、実際に機械学習を扱っている方の多くは、「作る」っていう作業に向き合ってきていないんですよね。
僕が「ツールボックスアプローチ」と呼んでいる、設定した課題に対して用意されているアルゴリズム群(いわゆる「ツール」)のマッチングを図る、という手法を取る方が非常に多いんです。
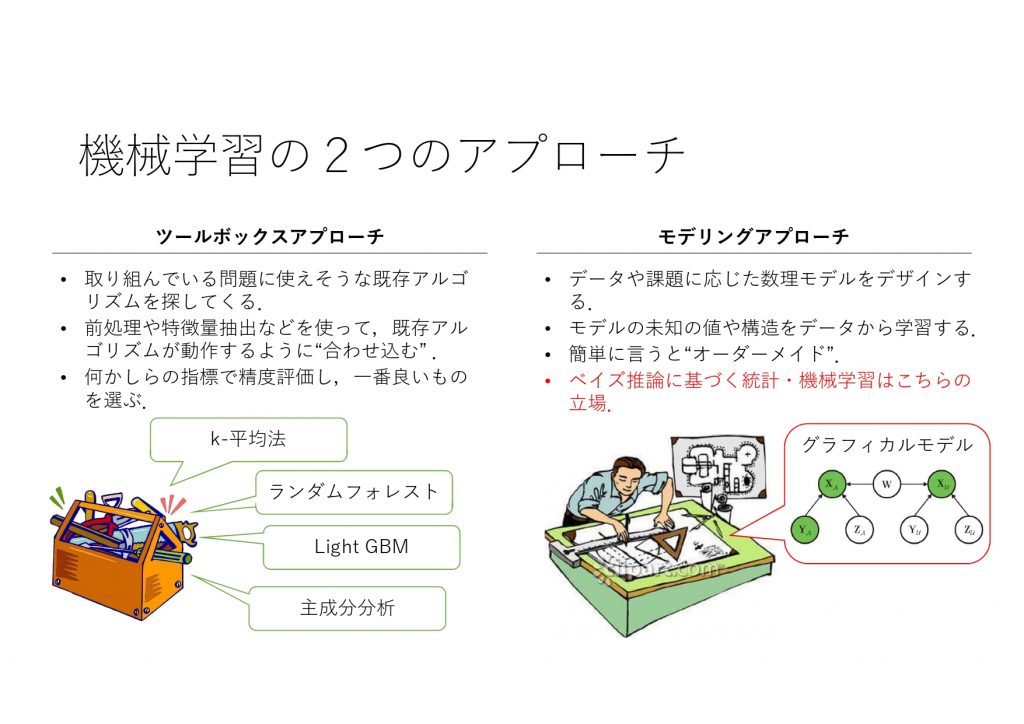
ただ、自分の場合は、設定された課題に応じて統計モデルを自分で構築する、というアプローチを取ることがほとんどです。
ありあわせのもので対応するのではなく、自身で解決策を「デザインする」というこだわりを「作って」という言葉に込めたわけですね。
「遊ぶ」という言葉も同様です。
一度自分で作った統計モデルなどは、いろいろな場面で利用することが出来ます。
ツールボックスアプローチですと、一つの課題に一つのツールが対応しているので、それ以上のことは出来ないわけです。
一方で、自身で作った統計モデルであれば予測・異状検知・欠損値補完などあらゆる課題を一度に解決できてしまうんですよね。
自身で作ったものをいろんな場面で展開していく面白さ、これが「遊ぶ」ということだと僕は考えていますね。
機械学習におけるサービス開発の課題点と今後の展望
ーー機械学習にまつわるプロジェクトで成功する場合の共通項とは?
課題設定が間違っていると確実に失敗してしまうので、常に課題を見直しながら進んでいけることでしょうか。
あとは、意外に思われるかもしれませんが、「諦めない気持ち」とか「忍耐力」みたいなものも必要だと思います。
特に頭脳明晰な人ほど諦めが速かったりするケースも多いので、いい意味で失敗に鈍感になって粘り強く取り組むことが大事ですね。
理解できないのであれば理解できるまで頑張ってみる、ある種の根性論みたいな感じでしょうかね。
こういった粘り強さややりきる力が成功する秘訣かもしれません。
確かにAIエンジニアは現状引く手あまたですので、「もう飽きたし、このプロジェクトやーめた!」となっても生活は出来てしまうんですけど、そうなると成長は止まってしまいますよね。
結局、やり切ってみないと答えは分かりませんしね。
ーー「設計」から「実装」までで完結するWeb開発案件と異なり、機械学習には「試行錯誤」のフローが入ることをあまり認識できていない発注者も多いのでは?
最近はようやく気付き始めてきたかな、という印象ですかね。
機械学習の難しい所は「モジュール性がない」ところなんです。
機械学習は「Xと入れたらYと吐き出す」みたいな単純な機能を持っているわけではありません。
実際に運用を始めれば、環境も変わるかもしれませんし、それによって精度が劣化することも多々あります。
仕様通りに動かないこともままありますし、そもそも仕様なんて設計できるのかどうかも分からないのが機械学習なんですよね。
そういった本質的な難しさがあるので、今まで通りの発注ではうまくいかないことがあるんじゃないでしょうか。
ーー機械学習を利用したサービスを提供したいと考えている方に一言お願いします。
まず、絶対に自分だけで全貌を把握するのは無理です。
課題ごとに当事者意識を持った専門家と協力していく、ということが重要になってくるはずです。
そもそも課題設計が間違っている状態で行われる機械学習の開発は無意味ですので、しっかりと専門家たちと協議した上で適宜修正することが求められてきます。
ーー須山さん自身の今後の構想ややっていきたいこととは?
基本的には今と変わりませんね。
直近で言えば、データサイエンスがあらゆる領域に還元できるツールなので、そのデータサイエンスを通じて何かが出来れば良いなとは思っていますね。
その中で、一生かけて取り組めるような課題が見つかることを期待しています。
課題探しのための一つのツールとしてのデータサイエンスや機械学習、といったところでしょうか。
また、良質な技術や理論を見つけたらブログなどでいろんな人に共有していく、ということも引き続き取り組んでいきたいですね。
僕一人で取り組める課題の数は限られているわけですから、皆さんに僕の情報を共有することで一人でも多くの人が課題発見や課題解決に携わってくれると嬉しいです。

総括
いかがでしたでしょうか?
私たちは新しい技術の登場を目の前にすると、どうしても枝葉末節の部分に目が行きがちですが、そういった新しい技術の登場が起きた時こそコアとなる理論の部分に立ち返ることの重要性を教えていただきました。
機械学習にまつわるプロジェクトに関しても、「まずはやり切ってみることが大事」と仰るなど粘り強い姿勢が機械学習を会得するうえでは大事なのだと気付かされましたね。
是非、これから機械学習に取り組みたいと考えている方や現在進行形で取り組んでいる方は、須山さんの言葉を参考にしながら「粘り強く試行錯誤しながら自分で作ってみる」ことを大事にしてみてくださいね!
![[Google 認定資格] GCP Professional Data Engineer の勉強方法と対策](https://estyle.co.jp/media/wp-content/uploads/2020/06/1a1b6b6c416fa0e83c5039642bbcaf6a-297x300.png)






