
記事の要点
- GitHub Issuesをトリガーに、GitHub Actionsの無料枠内で外部APIに依存せず複数のローカルSLMを並列推論させる「LunchOps」を構築した。
- 8つのSLMを並列稼働させた結果、極小モデルにおけるハルシネーションの発生やプロンプト追従性の差異など、モデル規模ごとの特性に関する知見を得た。
- 意思決定の完全自動化を目指した結果、人間が本当に必要としているのは「決定」ではなく「選択肢の絞り込み」であるという要件の本質に到達した。
はじめに
株式会社エスタイルのうっちゃんです。
毎朝自作のお弁当を持参できる、極めて計画的で自己規律の高いエンジニアの方々は別として、私たちの多くは毎日12時が近づくにつれ、ある重大な意思決定に直面します。
それは「今日の昼食、何にするか」問題です。
コードの品質やシステムの可用性には血道を上げる我々ですが、こと自身のエネルギー補給の最適化となると、途端に判断力を失います。原宿の街をあてどなく彷徨い歩いた末に、結局いつもの店に入る。そんな非効率的なループ処理を毎日繰り返しているわけです。
この日次バッチ処理のような意思決定コストを、どうにかして技術の力で削減できないものか。
この課題を解決するため、私は日常的に利用しているGitHub Issuesをトリガーとし、GitHub Actions(以降、GHA)の無料枠内で外部のLLM APIに依存せずローカルSLM(小規模言語モデル)を駆動させるパイプライン「LunchOps」を構築しました。
本記事では、そのアーキテクチャの解説から、複数のSLMがもたらした予想外の提案までをレポートします。
設計
仕組みの概要
通常、テキスト生成を伴うボットの開発にはOpenAIなどの外部APIが利用されますが、今回はランニングコストを抑えつつセキュアな環境を構築するため、すべてをGHAの無料ランナー上で完結させるアプローチをとっています。
GHAの無料ランナー(Ubuntu: 4 vCPU / 16GB RAM)は本来CI/CD用ですが、今回はこれを一時的な推論サーバーとして間借りし、パラメータ数を数十億規模に抑えたSLMをCPUのみで推論させます。
4 vCPUという限られたリソースで動かすため、C/C++実装の軽量推論エンジンllama.cppと、モデルの計算精度を落としてサイズを圧縮する量子化を組み合わせています。各技術の詳細は記事末尾の付録にまとめています。
アーキテクチャ
本プロジェクトの設計において重視したのは、コンポーネント間の責務の分離です。
以下が、今回構築したシステムの最終的な全体構成図と、それを反映したリポジトリのディレクトリ構成です。
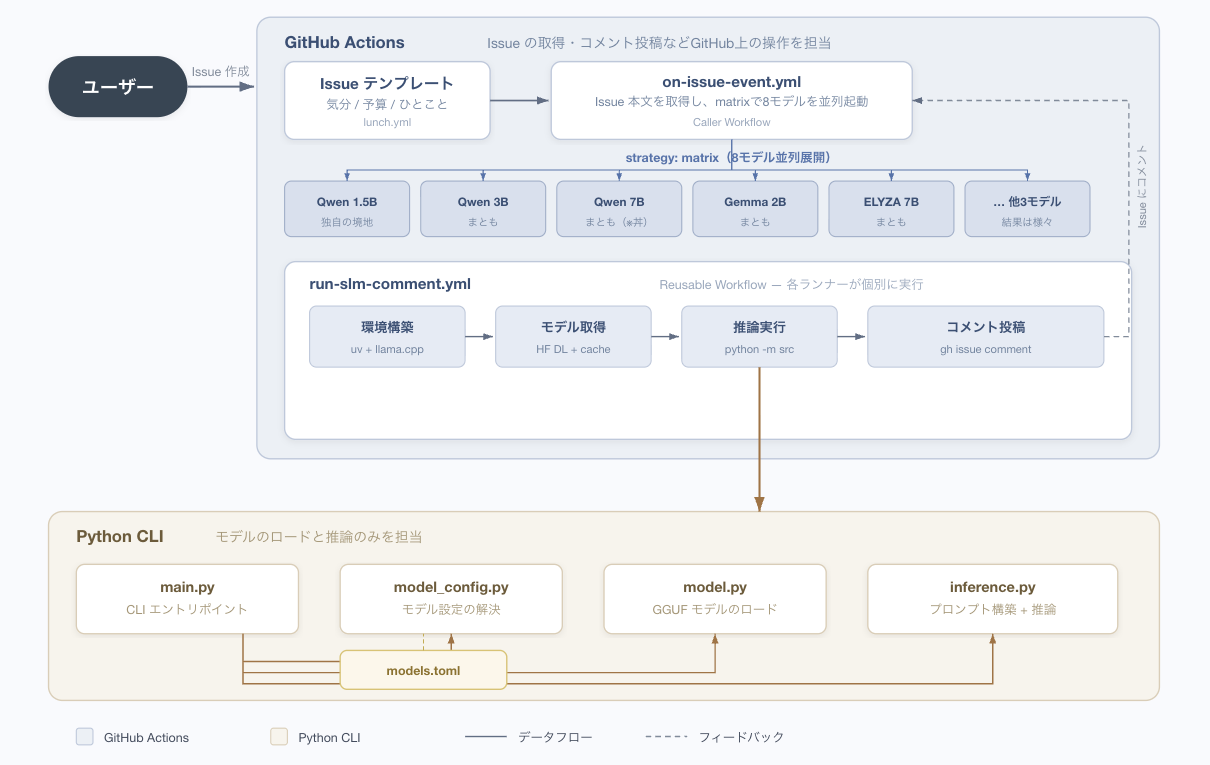
LunchOpsの全体構成図
issue-lunch-bot/
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ └── lunch.yml # トリガーとなるissueテンプレート
│ ├── dependabot.yml # 依存関係の自動更新
│ └── workflows/
│ ├── on-issue-event.yml # API操作・イベント制御
│ ├── run-slm-comment.yml # 推論環境の構築・実行のリユーザブルワークフロー
│ └── ci.yml # テスト・Lint実行
├── src/
│ ├── inference.py # 推論ロジック
│ ├── main.py # CLIエントリポイント
│ └── model.py
├── tests/
│ └── test_inference.py # ローカル実行可能な単体テスト
└── models.toml # モデルごとの仕様定義
Python側は標準入力からテキストを受け取り、標準出力に結果を返す純粋なCLIツールとして実装しました。issue内容の取得やコメントの投稿といったGitHub API操作は、すべてGHA側のワークフローに委譲しています。これにより、ローカル環境での単体テストが容易になり、推論ロジックとプラットフォーム依存の処理を独立して開発・検証できる構成としています。
また、pytestによるテスト実行、ruffによる静的解析、Dependabotによる依存関係の監視など、一般的なWebアプリケーションと同等のCIパイプラインも構築しています。
なお、エスタイルではClaudeのTeamプランに加入しており、本プロジェクトの設計の壁打ちから具体コードの作成、READMEの記述に至るまでClaude Codeを活用しています。AIをペアプログラマーとして用いることで、要件定義から実装までの時間を大幅に短縮できました。
開発と検証
フェーズ1:1人に相談してみる
実装完了後、まずは単一のモデルのみを起動するシンプルな構成で運用を開始しました。
実際にissueを立ててみると、1〜2分ほどで提案が返ってきます。
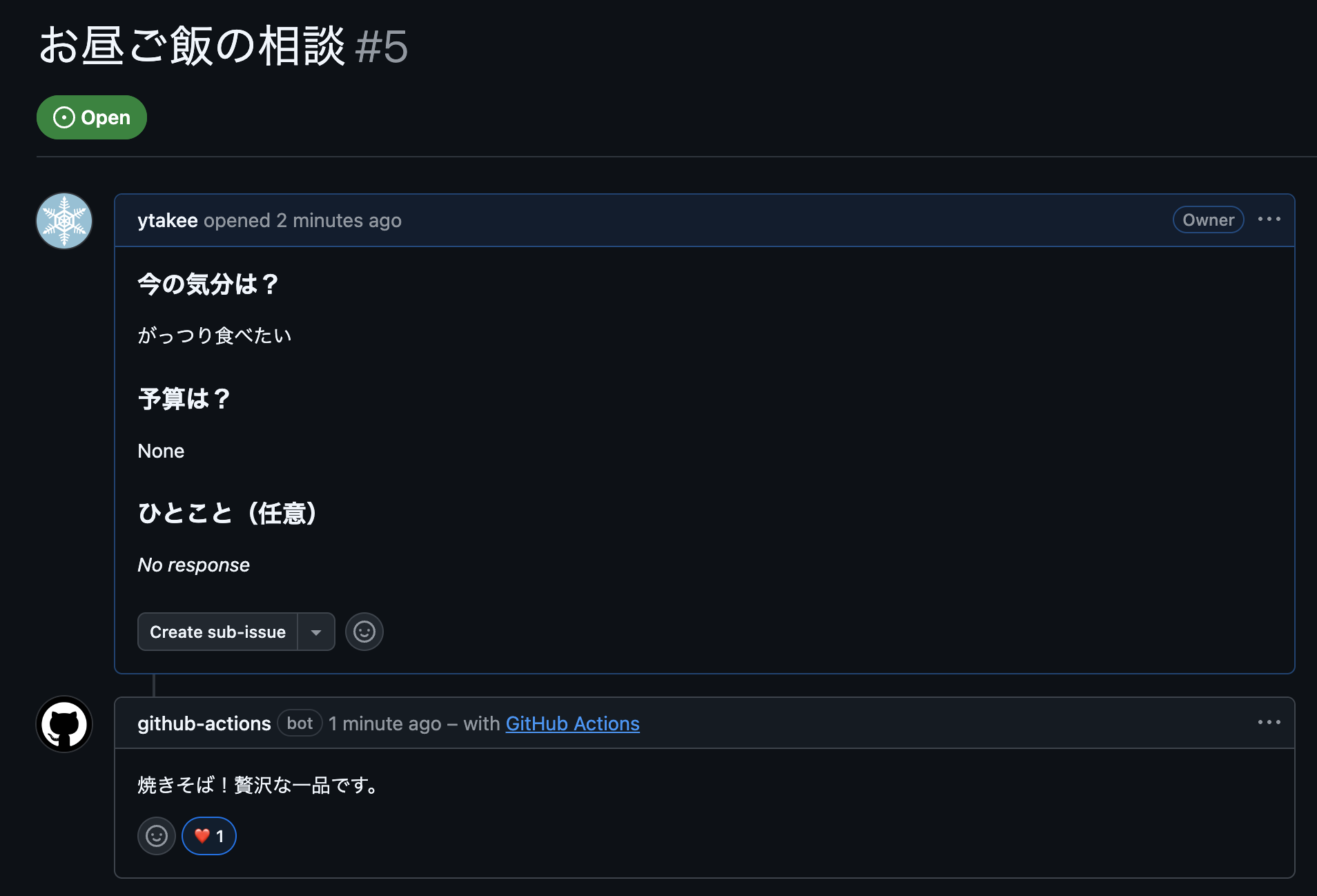
「がっつり食べたい」に対する提案。焼きそば。贅沢な一品らしい。
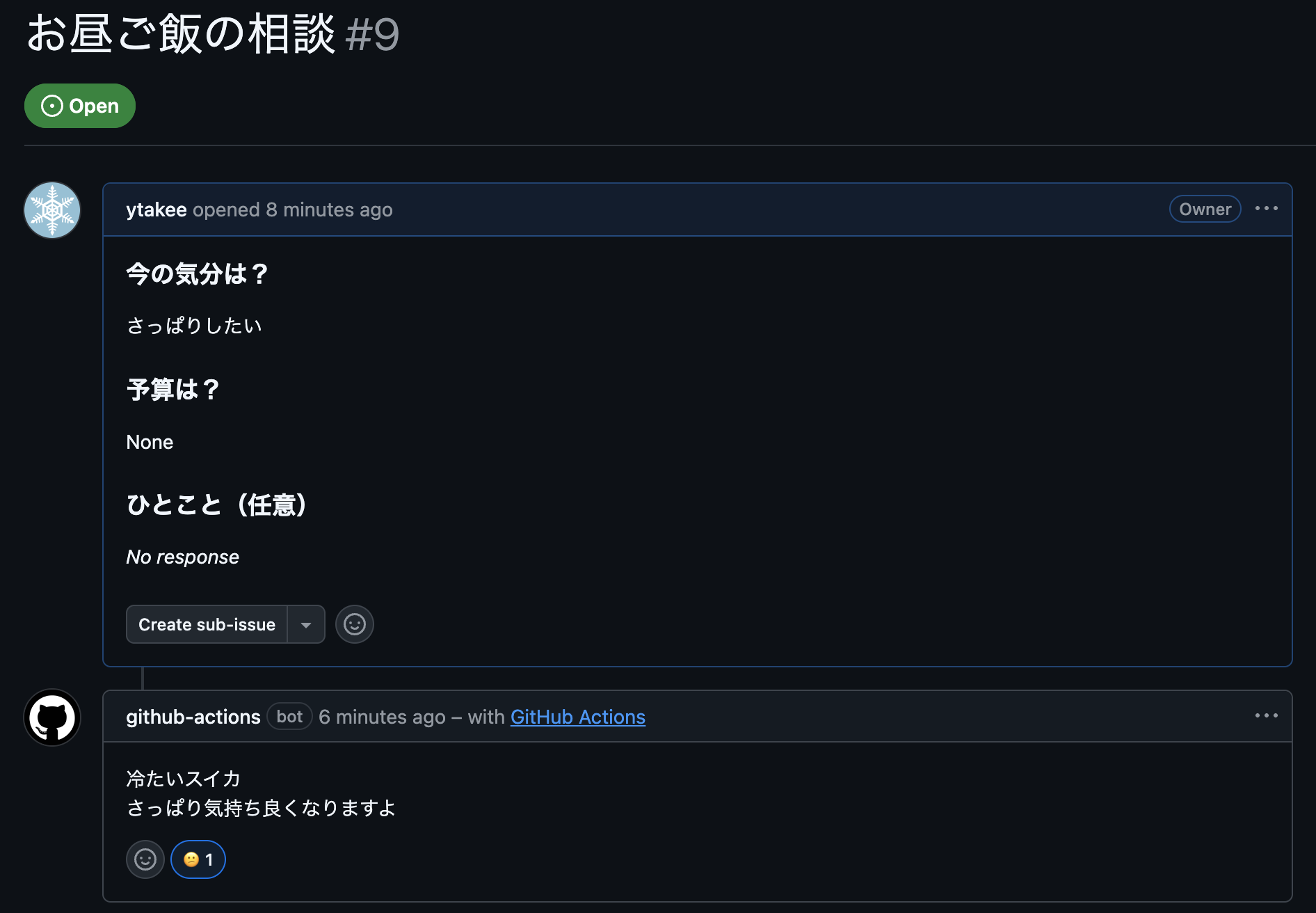
「さっぱりしたい」に対する提案。冷たいスイカ。
当然ながら、外部ネットワークから切り離されたローカルSLMは原宿の飲食店など知る由もありません。そのため、提案された「焼きそば」という概念を、私が脳内で「あそこの中華料理屋に行くか」とマッピングする力技での運用となります。
推論基盤としては問題なく動作していましたが、単一モデルでの動作検証が完了したところで、一つの懸念が浮かびました。
「一つのSLMの意見に自身の昼食を完全に委ねることは、食事の満足度を損ねかねない」というものです。
「焼きそば」は良いのですが、「冷たいスイカ」を昼食として提案された日に、後悔なくスイカだけで午後を乗り切れるのか。
一つのSLMの提案だけでは、その日に最適なランチを得られると言い切ることができませんでした。
フェーズ2:8人に同時に聞く
この提案の妥当性への懸念に対して、通常であれば「主食となるメニューを出力しろ」とシステムプロンプトを改修するのが定石です。
しかし、極小モデルに対するプロンプトエンジニアリングは、指示を渡しても無視される頻度が高く安定しません。そこで私はプロンプトの調整を早々に諦め、インフラの力技による解決を選択しました。
GHAのstrategy: matrix機能を活用し、複数の異なるモデルを同時に起動するアーキテクチャへの拡張を行いました。
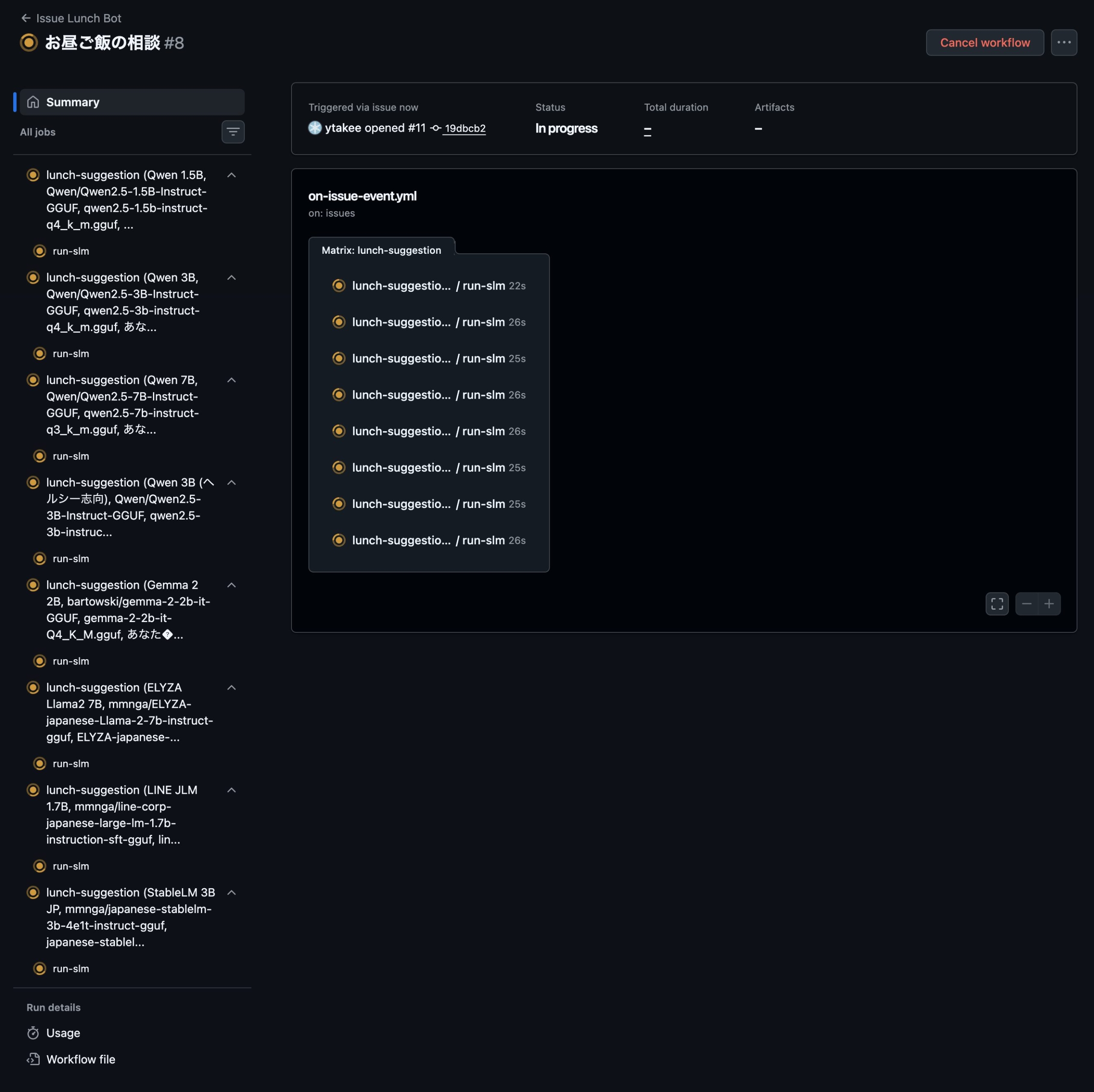
1つのissueに対して並列起動する8つのランナー
パラメータサイズや学習データが異なる以下の8つのモデルをマトリクスとして定義し、1つのissueをトリガーとして一斉に推論を開始させます。モデルのサイズ、プロンプトの差分による違いをみるためにQwenは複数採択しています。
- Qwen 2.5 7B
- ELYZA Llama2 7B
- Qwen 2.5 3B
- Qwen 2.5 3B(ヘルシー志向のプロンプトを設定)
- Gemma 2 2B
- StableLM 3B JP
- LINE JLM 1.7B
- Qwen 2.5 1.5B
これにより意思決定の自動化はできないものの、多様な視点から選択肢の絞り込みができるはずです。
8つのSLMが提案した昼食たち
拡張した並列推論基盤に対し、GitHub Issues上で「冷たいものが食べたい」「あったかいものが食べたい」といった気分を入力しました。1〜2分ほどで、issueのコメント欄に各モデルからの提案が一斉に投稿されます。
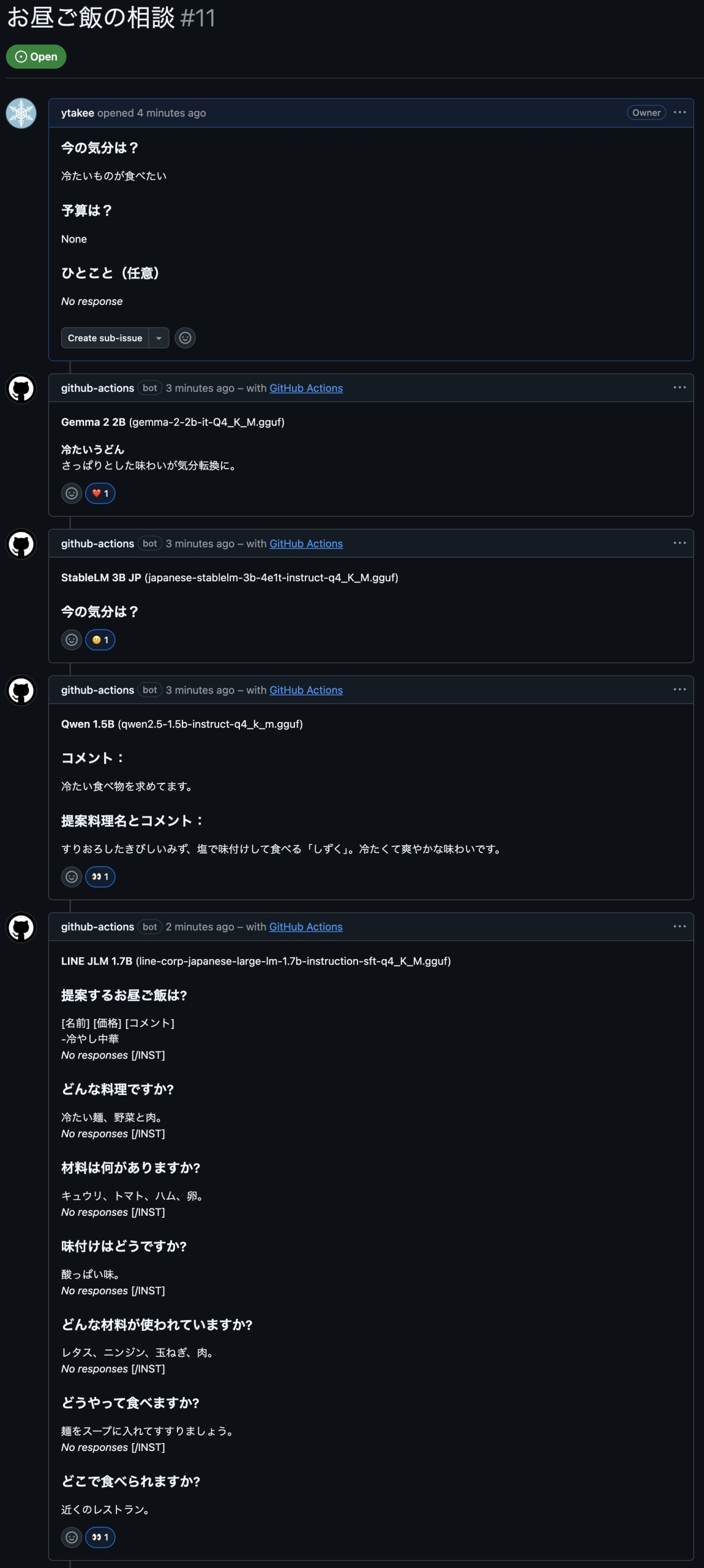
「冷たいものが食べたい」に対する各モデルからの提案コメント
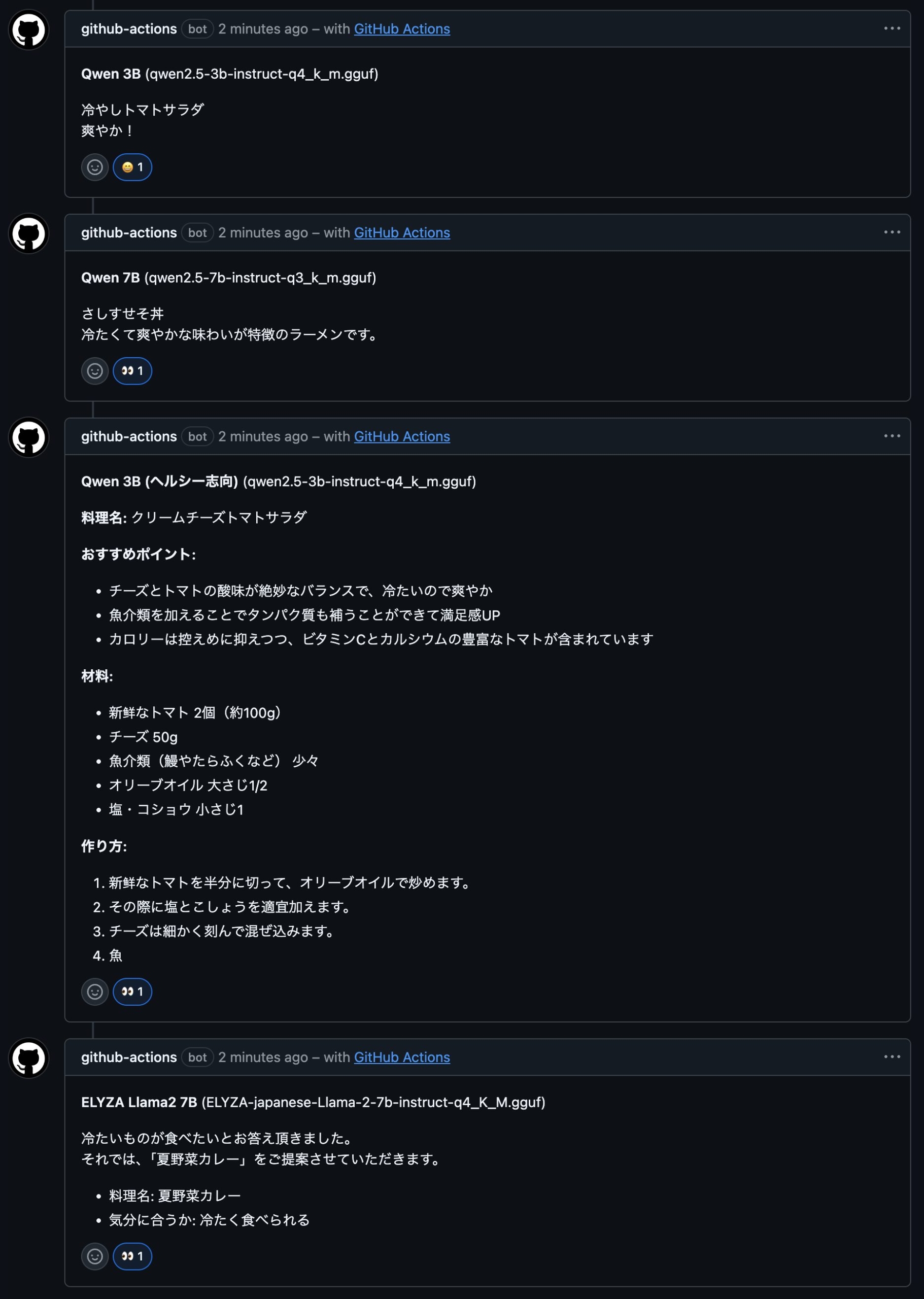
同issueの続き。モデルごとに回答の質が大きく異なる。
※「あったかいものが食べたい」に対しての各モデルからの提案は本記事の付録に掲載しています。
これらの質問に対して出た8つのモデルの回答を、「まともに答えた」「会話が成立しなかった」「独自の境地」の3パターンに分類しました。
| モデル名 | パラメータ数 | 量子化 | 本文での分類 |
| Qwen 2.5 7B | 7B | Q3_K_M | まともに答えた(※「さしすせそ丼」) |
| ELYZA Llama2 7B | 7B | Q4_K_M | まともに答えた |
| Qwen 2.5 3B | 3B | Q4_K_M | まともに答えた |
| Qwen 2.5 3B(ヘルシー志向) | 3B | Q4_K_M | まともに答えた |
| Gemma 2 2B | 2B | Q4_K_M | まともに答えた |
| StableLM 3B JP | 7B | Q4_K_M | 会話が成立しなかった |
| LINE JLM 1.7B | 1.7B | Q4_K_M | 会話が成立しなかった |
| Qwen 2.5 1.5B | 1.5B | Q4_K_M | 独自の境地 |
会話が成立しなかったモデルたち
まず、提案以前に問題を抱えているモデルたちから紹介します。
LINE JLM 1.7Bは、[名前] [価格] [コメント] やNo responses [/INST]といった学習時の特殊トークンやテンプレートの残骸をそのまま出力しています。モデルごとのプロンプトフォーマットの違いが、出力結果に直接影響していることが観察できます。
さらにStableLM 3B JPに至っては、「冷たいものが食べたい」という入力に対して「今の気分は?」とこちらの回答や質問に対してをオウム返しにするだけで、提案そのものを放棄してしまいました。
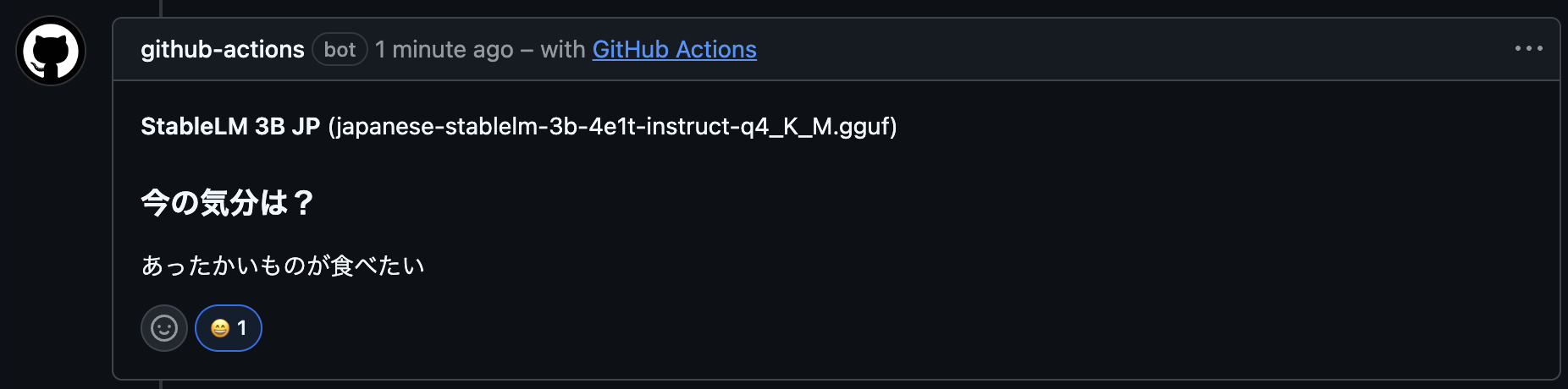
「あったかいものが食べたい」でも同じ。StableLMは再び「今の気分は? あったかいものが食べたい」とオウム返し
入力を変えても判で押したようにオウム返しを繰り返すこの姿勢は、ある意味で一貫性があると言えなくもありません。
まともに答えたモデルたち
一方で、昼食の相談相手として機能したモデルも多数ありました。
Qwen 3Bは「冷やしトマトサラダ」を端的に提案し、「冷たいものが食べたい」という要望に直接対応した回答を返しています。
ELYZA Llama2 7Bは「夏野菜カレー」を丁寧な敬語で提案しており、同じ「冷たいもの」という入力に対して「冷たく食べられるカレー」という間接的なアプローチを取った点が興味深いです。
Gemma 2 2Bの「冷たいうどん」のように、2Bという小規模でも的確な回答を返すモデルもあります。
3B〜7Bクラスのモデルは概ね実用的な回答を返しており、この辺りが昼食の相談相手として信頼できるラインです。
ただし、まともな回答の中にもグラデーションは存在します。
Qwen 7Bは普段はまともに回答しています。しかし今回は、「さしすせそ丼」なる謎のメニューを提案した上で、その説明を「冷たくて爽やかな味わいが特徴のラーメンです。」と締めくくっています。丼なのにラーメン。大きいモデルであっても、油断するとジャンルの境界を軽々と越えてくるようです。
独自の境地に到達したモデル
本検証で最も興味深い回答を提示したのは、今回採用した中で最もパラメータ数の少ないQwen 1.5Bでした。
「冷たいものが食べたい」という私の要望に対し、以下のような提案がなされました。
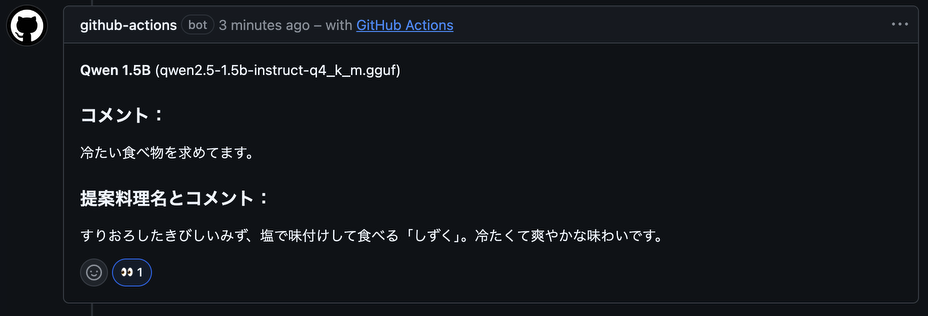
Qwen 1.5Bによる提案「しずく」
すりおろしたきびしいみず、塩で味付けして食べる「しずく」。冷たくて爽やかな味わいです。
実在するのであればぜひ味わってみたいこの不思議な料理は、非常にわかりやすいハルシネーションの例です。
言語モデルは実際に料理を行って知識を獲得したわけではなく、世の中の文字情報からそれらしい知識を確率的に結びつけています。
そのため、「冷たい」「爽やか」「塩分」といった夏の食事に関連する単語のベクトルが強く引き合った結果、「水をすりおろす」「塩水を食事とする」という物理的・味覚的な制約を完全に無視した出力が生成されたと考えられます。
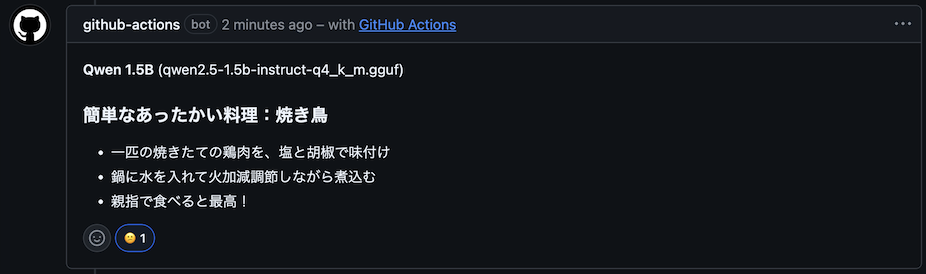
別の入力「あったかいものが食べたい」に対するQwen 1.5Bの提案。「親指で食べると最高!」
なおこのQwen 1.5Bは、別の入力「あったかいものが食べたい」に対しても「焼き鳥」を提案しつつ「親指で食べると最高!」と独自の食事作法を提唱しています。箸でも手でもなく、親指。一貫して我が道を行く姿勢には、もはや敬意すら覚えます。
ハルシネーションはパラメータ数が少ないモデルの方が起きやすく、極小モデルの世界は予想以上に豊かでした。
完全自動化という夢とその終焉
実は設計の初期段階では、さらに先のフローを構想していました。複数モデルを並列で走らせた後、そのすべての回答をもう一つのモデルに集約させ、最終的な結論を一つだけ出力してissueをクローズする——意思決定の完全自動化です。
しかし、各モデルの推論結果を観察した結果、この実装は見送りました。
前述の「しずく」のような物理法則を無視したハルシネーションを最終モデルが真に受け、貴重な1時間の昼休みに「塩を振ったすりおろし水」をすすることになるリスクを排除しきれなかったためです。自身のエネルギー補給の全権をAIに委ねるほどの勇気は、残念ながら私にはありませんでした。
結果として、各モデルの出力は統合せずに並列のまま提示し、最終的な選択は人間がissueのコメント欄を見て行う仕様で稼働させています。
そしてこの運用を通じて気づいたことがあります。自分が本当に欲しかったのはAIに昼食を決めてもらうことではなく、無限に見える選択肢の中から、今の気分に合った候補をいくつかに絞ってもらうことだったということです。
完全な自動化を目指して走った結果、たどり着いたのは人間とAIの適切な役割分担でした。
まとめ
本検証により、外部APIに依存せずともGitHub Actionsの無料枠にて、複数のSLMから昼食の提案を受ける仕組みが構築可能であることが確認できました。
今回構築した仕組みはSLMが単純に回答しているのみのため、拡張の余地は多く残されています。システムプロンプトの切り替えによる観点の多様化、原宿周辺の店舗情報を踏まえて回答するためのWeb検索の追加、それぞれのモデルからの意見を集約して結論を出す仕組みの構築などが考えられます。
今回は「今日の昼食を決める」という日常のささいな課題からスタートしましたが、手を動かして検証することで、ローカルSLMの特性や、複数のAIを協調させるシステムの面白さを実感できました。
この記事のプロジェクトに興味を持った方は、ぜひリポジトリを覗いてみてください。
エスタイルではこういった技術的な探究心を一緒に楽しめる仲間を探しています。まずはカジュアルにお話しましょう!
付録:技術詳細
本記事で紹介した「LunchOps」はこちらのリポジトリで公開しています:https://github.com/ytakee/issue-lunch-bot
リポジトリオーナーのissueでしか動作しないようにしているため、試してみたい方はforkしてからの実行をお願いします。
以降は、本文で触れた技術要素についてより詳しく解説します。
主要技術
GitHub Actions(GHA)
コードの追加やIssueの作成などをトリガーにして、クラウド上で処理を自動実行できるGitHubの標準機能です。今回はこの無料ランナー(Ubuntu: 4 vCPU / 16GB RAM)を、本来のCI/CDツールとしてではなく、一時的な推論サーバーとして利用しています。
SLM(小規模言語モデル)
ChatGPTなどの背後で動いている巨大なLLMは、高価なGPUを必要とします。一方で、パラメータ数を数十億規模に抑えたSLMであれば、一般的なCPUでも推論が可能です。今回は外部にデータを送信せず、GHAのサーバー内で処理を完結させるために採用しています。
llama.cpp
非常に軽量なC/C++実装の推論エンジン。GPU環境での高速化はもちろん、今回のようなCPUのみの環境においても高いパフォーマンスを発揮します。
量子化(GGUF形式)
AIモデルの計算精度をあえて落とし、モデルのファイルサイズと必要メモリを劇的に圧縮する技術です。
GHA上での実行の効率化
GHAの無料ランナーは月あたりの実行時間に上限があり、また空腹時の待ち時間は少しでも短い方が望ましいため、以下の工夫を行いました。
ハードウェアレベルの演算高速化
CMAKE_ARGSを調整し、CPUの並列計算機能(SIMD命令)を有効化。行列演算の処理速度を底上げしています。
コンテキスト長の制限
今回の目的は「単発のランチ提案」であり、過去の文脈を記憶する必要がないため、モデルが一度に処理できるトークン数(n_ctx)を512に制限し、初期化にかかるメモリと時間を削減しました。
セットアップの短縮
パッケージ管理ツールに動作の高速なuvを採用し、数GBに及ぶモデルファイルはGHAのキャッシュ機能(actions/cache)を利用してダウンロード時間を短縮しています。
「あったかいものが食べたい」への回答
「チキンカレーライス」「味噌ラーメン」に心がほっこりしました。







