
記事の要点
- 手作業でコストのかかるRAG精度評価を、Synthetic DataとLLM-as-a-Judgeで半自動化し、工数を劇的に削減できる。
- gemini-3-flash-previewなどの高性能かつ安価なLLMを活用することで、低コストで実用的な評価パイプラインを構築できる。
- 評価指標の厳密な定義とプロンプトエンジニアリングにより、幻覚の検知や回答精度の測定を自律的に行うシステムが実現できる。
はじめに
株式会社エスタイルのごんです。
近年、企業内ドキュメントを活用したRAG(Retrieval-Augmented Generation)システムの導入が進んでいますが、その「回答精度の評価」が大きな課題となっています。
本記事では、LLMを用いてテストデータ生成から採点までを自動化する「Evaluation Pipeline」を構築し、評価工数の削減と品質担保の両立を検証します。
開発の背景と目的
RAG開発における「評価の壁」
生成AIを用いたアプリケーション開発、特に社内FAQボットなどのRAGシステムにおいて
開発者を最も悩ませるのが「精度の評価」です。
プロトタイプを作るのは簡単ですが、いざ本番運用を考えたとき以下のような問題に直面します。
- 「このRAGは、本当に正しい回答をしているのか?」
- 「ドキュメントを更新した後、以前の質問に正しく答えられているか?」
- 「回答のハルシネーション(もっともらしい嘘)をどう検知するか?」
これらを人間が手作業で確認しようとすると、数百件の質問と回答のペアを作成し、それぞれの回答を目視でチェックする必要があります。
これは非常に時間がかかり精神的にも負荷の高い作業です。また、評価担当者によってOK/NGの基準がブレるという属人化の問題も発生します。
自動評価への期待
そこで注目されているのが、
Synthetic Data(合成データ)
LLM-as-a-Judge(裁判官としてのLLM)
を組み合わせた自動評価のアプローチです。
人間がテストデータを作るのではなく、LLMにドキュメントを読ませて「ありそうな質問と正解のペア」を作らせる。
そして、RAGが生成した回答の良し悪しもLLMに判定させる。
このサイクルを回すことで、評価プロセスを自動化し継続的な改善(CI/CD)が可能になります。
今回はこのパイプラインをGoogleの最新モデルであるGemini 3 Flash Previewを用いて実装し、その実用性を検証しました。
LLMが回答を採点する「AI裁判官」のイメージ
実装のアプローチ
全体アーキテクチャ
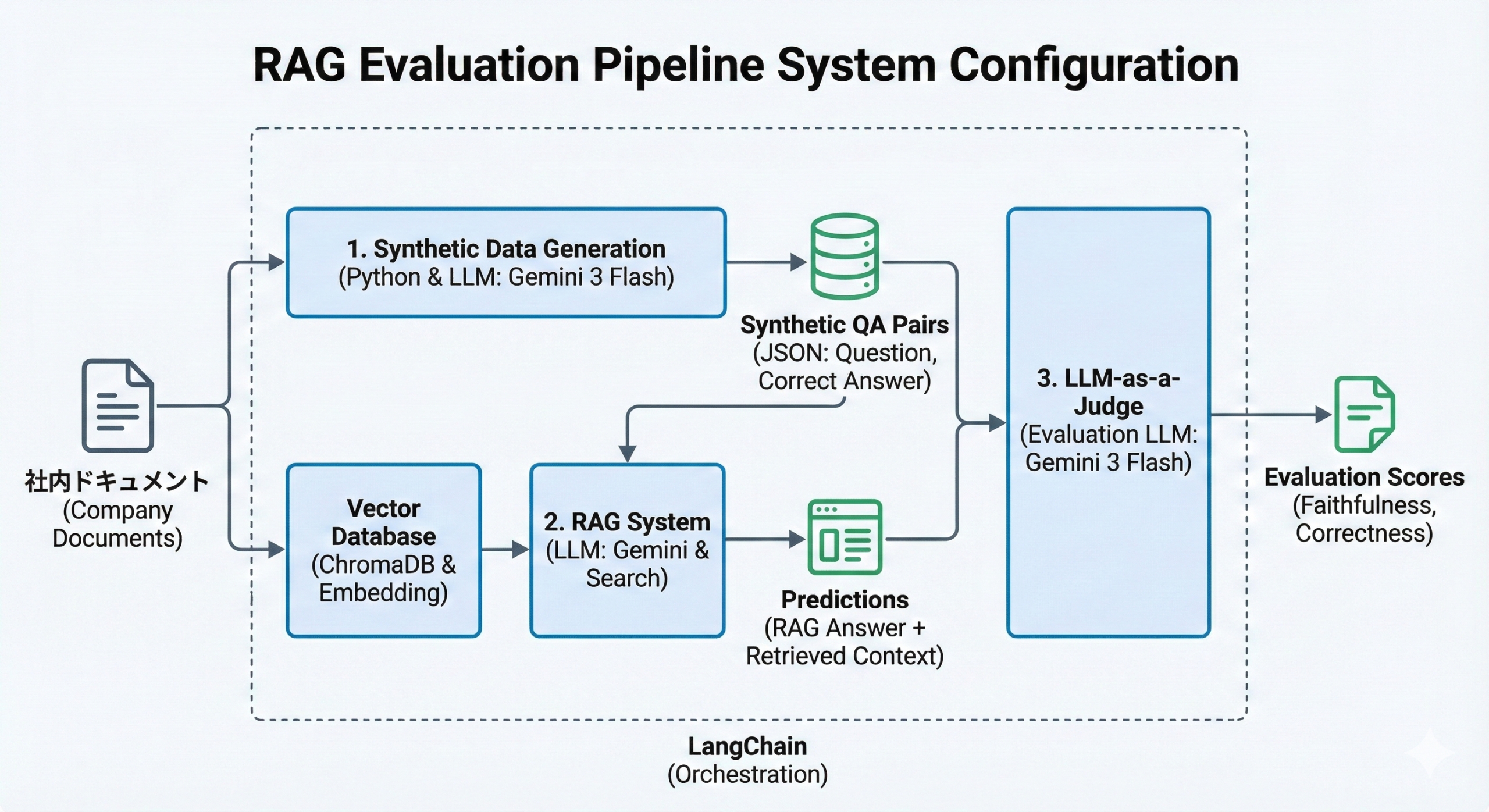
今回の検証で構築したパイプラインの全体像は以下の通りです。
大きく分けて「データ準備フェーズ」と「評価実行フェーズ」の、2段階で構成されています。
1.「データ準備フェーズ」
・Synthetic Data Generation: 社内規定ドキュメントを読み込み、LLMが質問と正解のペアを自動生成します。
2.「評価実行フェーズ」
・RAG Execution: 生成された質問をRAGシステムに入力し、回答(Prediction)を得ます。
・LLM-as-a-Judge: ステップ1で生成した「質問」「正解」と、ステップ2で得た「回答」「検索されたコンテキスト」の4つを評価用LLMに入力し精度をスコアリングします。

RAG自動評価パイプラインの全体像(ドキュメントからQAを作り、検索・回答を経て自動採点を行う)
技術スタックの選定
今回は、誰でも再現可能かつ低コストで運用できることを重視して技術選定を行いました。
- プログラミング言語: Python
- 選定理由: AI開発のデファクトスタンダードであり、ライブラリが豊富です。
- LLM & Embedding: gemini-3-flash-preview / gemini-embedding-001
- 選定理由: 圧倒的な処理速度とコストパフォーマンス。特にFlashモデルは大量のテキストを処理するSynthetic QA生成に向いています。また、Free Tier(無料枠)が利用できるため、個人の検証にも最適です。
- 注記: Synthetic QA生成とLLM-as-a-Judgeで同一モデルを使うと「同一モデル起因のバイアス」が生じます。理想はJudgeを別モデルにして相互評価し、コストと再現性のバランスで選定します。
- Vector Database: ChromaDB
- 選定理由: ローカル環境で手軽に動作し、セットアップが容易です。
- Orchestration: LangChain
- 選定理由: LLMの呼び出しやプロンプト管理を効率化するために採用しました。
具体的な実装ステップ
ここからは、実際に構築したコードの内容をステップごとに解説していきます。
1. テストデータの自動生成
まず最初に行うのは、評価の基準となる「テストデータ」の作成です。
従来であれば、人間がドキュメントを読み込んでエクセルに質問と回答をポチポチと入力していましたが、今回はこのテストデータの作成作業をPythonスクリプトで自動化します。
プロンプト設計の重要性
「質の低いテストデータ」からは「質の低い評価」しか生まれません。
そのため、データ生成のプロンプトには細心の注意を払いました。
具体的には、以下の制約をLLMに課しています。
- 情報の限定: 「提供されたテキストに含まれる情報のみに基づいて」という指示を徹底し、LLMが事前学習知識で勝手に回答を作るのを防ぎます。
- フォーマットの統一: 後続のプログラムで処理しやすいよう、完全なJSON形式での出力を強制します。
- 粒度の調整: ドキュメントを適切なサイズ(Chunk)に分割し、それぞれの塊ごとに質問を作らせることで、ドキュメント全体を網羅的にテストできるようにします。
実際の生成コードの一部を見てみましょう。
# src/generate_qa.py(データ生成ロジックの抜粋)
def generate_qa_pairs(text_chunk):
# LLMへの指示(プロンプト)
prompt_template = """
あなたはRAGシステムの評価データ作成担当者です。
以下のテキストに基づいて、従業員が問い合わせそうな「質問」と、
それに対するテキストに基づいた正しい「回答」のペアを作成してください。
【重要】回答は必ずテキスト内の情報のみを使用すること。
"""
# ... (Gemini APIの呼び出し処理)
return json.loads(response.content)
このスクリプトを実行すると、例えば「リモートワーク規定」のドキュメントから、以下のようなJSONデータが次々と生成されます。
{
"question": "カフェで仕事をしてもいいですか?",
"answer": "はい、事前にセキュリティ環境が確保されていることを条件とし、上長の許可を得れば可能です。"
}
人間が頭を悩ませて考える必要はありません。
ドキュメントをフォルダに入れてスクリプトを叩くだけで、数十件から数百件のテストケースが即座に手に入ります。
2. RAGシステムの構築
次に、評価対象となるRAGシステムを実装します。
今回は評価に主眼を置くため、ChromaDBを使った標準的な構成としました。
ここでは、ドキュメントをベクトル化してデータベースに保存し、ユーザーの質問に近い情報を検索して回答を生成します。
この検索部分の精度がRAGの性能を大きく左右するため、
本番運用ではチャンクサイズの調整や検索アルゴリズムの工夫が必要になりますが、今回はシンプルな類似度検索を用いています。
3. LLMによる自動評価
ここが本記事のメインパートです。
RAGが生成した回答が正しいかどうかを、人間ではなくAI(LLM)に判定させます。
システム構成図
評価指標の定義
「AIが良い回答だ」と判定するための基準を明確にする必要があります。
今回は以下の2つの指標を採用しました。
- Faithfulness (誠実性)
- 概要: 「AIが嘘をついていないか」を測る指標です。
- 判定基準: 生成された回答に含まれる情報が、検索されたドキュメント(コンテキスト)の中に存在するかを確認します。もしコンテキストに書いていないことを回答していれば、それは「ハルシネーション(幻覚)」とみなされスコアは0になります。
- Correctness (正確性)
- 概要: 「ユーザーの質問に正しく答えているか」を測る指標です。
- 判定基準: 生成された回答の意味内容が、事前に用意した正解データと一致しているかを確認します。
評価プロンプトの実装
これらの指標をLLMに理解させるため、採点用のプロンプトを作成しました。
「あなたは厳格な採点者です」という役割を与え、入力されたデータと比較して 0(不合格)か 1(合格)の二値で判定させます。
数値化することで、システム全体の「正答率」を定量的に算出できるようになります。検証結果と考察
実際に架空の「社内リモートワーク規定」を用いて、RAGシステムの精度評価を行ってみました。
定量評価の結果
- Faithfulness (誠実性): 100% (5/5問)
- Correctness (正確性): 80% (4/5問)
Gemini 3 Flash Previewの能力は非常に高く、ほとんどのケースで的確な検索と回答生成が行われました。
特にFaithfulnessが満点だったことから、提供されたドキュメントに基づいて忠実に回答する能力(RAGとしての基本動作)は十分に満たしていると言えます。
失敗ケースの深掘り
しかし、1問だけCorrectnessで不合格となったケースがありました。
ここを分析することが、システム改善の鍵となります。
- 質問: 「緊急時の連絡先電話番号は何番ですか?」
- ドキュメントの記述: 該当する記載なし
- 正解データ: 「規定には記載されていません」
- RAGの回答: 「緊急時の連絡先電話番号は規定に記載されていませんが、電話、Slack、Zoom等により常に連絡が取れる状態にしておく必要があります。」
このケースでは、RAG自体は「記載がない」という事実は認識できていました。
しかし、関連する条文(連絡手段に関する規定)を引っ張ってきて、ユーザーに役立つ補足情報を付け加えました。
人間が見れば「親切な回答」ですが、厳密な自動採点ロジックでは
「正解データ(記載なし)と完全に一致しない」=「余計な情報が含まれている」
と判断され、NGとなってしまいました。
ここから得られる教訓は、「自動評価プロンプトの調整の難しさ」です。
単純なキーワードマッチングや厳格すぎる一致判定を行うと、RAGの良い振る舞いを「間違い」としてカウントしてしまう可能性があります。
「意味が合っていればOKとする」「補足情報は許容する」といった柔軟な指示をプロンプトに組み込むことが、より人間に近い評価を実現するために必要です。
実運用のためのTipsと今後の展望
Free Tier活用の注意点
今回使用したGemini APIのFree Tierは非常に強力ですが、APIのリクエスト回数制限(Rate Limit)が厳しめに設定されています。
特にEmbedding(ベクトル化)や大量の評価を短時間に行うと 429 Too Many Requests エラーが発生しやすいです。
スクリプト内で time.sleep() を適切に挟んでリクエスト間隔を調整するか、本格的な運用の際はPay-as-you-go(従量課金)プランへの移行を推奨します。
それでも他社LLMと比較してコストパフォーマンスは極めて高いです。
MLOpsへの展開
この評価パイプラインをさらに発展させれば、真の「MLOps」が実現できます。
例えば、社内ドキュメントが更新されてGitHubにプッシュされたトリガーで、この評価スクリプトをGitHub Actionsなどで自動実行します。
これにより、「規定の変更によって、既存のFAQ回答がおかしくなっていないか?」という回帰テストを完全に自動で行うことができます。
本番環境にデプロイする前に精度の劣化を検知できる仕組みは、大規模なRAGシステムを運用する上で強力な武器になるでしょう。
まとめ
本記事では、Synthetic DataとLLM-as-a-Judgeを組み合わせたRAGの自動評価パイプラインについて解説しました。
以前は数日かかっていた評価作業が、この仕組みを使えば数分で、コーヒーを飲んでいる間に完了します。
完璧な自動化は難しい部分もありますが、一次スクリーニングとして活用するだけでも劇的な工数削減効果があります。
ぜひ皆さんのプロジェクトでも試してみてください。
参考文献
- Google AI Studio – Gemini API Pricing(https://ai.google.dev/pricing)
- LangChain Documentation(https://python.langchain.com/)
- RAGAS – Evaluation Framework for RAG(https://docs.ragas.io/en/latest/)
※本記事は技術検証を目的としており、掲載しているコードや設定は実環境に合わせて調整が必要です。
Appendix(参考コード)
# src/generate_qa.py
import os
import json
import time
import ast
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import ChatPromptTemplate
from dotenv import load_dotenv
load_dotenv()
# ユーザーは環境設定ファイルまたは環境変数で認証キーを設定する必要があります
if not os.getenv("GOOGLE_API_KEY"):
print("WARNING: GOOGLE_API_KEY not found. Please set it in .env")
# Gemini(生成モデル)を初期化
llm = ChatGoogleGenerativeAI(model="gemini-3-flash-preview", temperature=0.7)
def load_data(path):
with open(path, "r", encoding="utf-8") as f:
return f.read()
def generate_qa_pairs(text_chunk):
"""
指定されたテキストチャンクからGeminiを使って質問・回答ペアを生成します。
"""
prompt_template = """
あなたはRAGシステムの評価データ作成担当者です。
以下のテキストテキストは社内規定の一部です。
このテキストに基づいて、従業員が問い合わせそうな「質問」と、それに対するテキストに基づいた正しい「回答」のペアを2つ作成してください。
【制約事項】
- 回答は必ず提供されたテキストに含まれる情報のみに基づいて作成してください。
- 出力は純粋なJSONリスト形式(Markdownコードブロックなし)にしてください。
- キーと値は必ずダブルクォート(")で囲んでください。
【出力フォーマット】
[
{{"question": "ここに質問を書く", "answer": "ここに回答を書く"}},
{{"question": "ここに質問を書く", "answer": "ここに回答を書く"}}
]
【対象テキスト】
{text}
"""
prompt = ChatPromptTemplate.from_template(prompt_template)
chain = prompt | llm
try:
response = chain.invoke({"text": text_chunk})
content = response.content
if isinstance(content, list):
content = "".join([str(item) for item in content])
# マークダウンのコードブロックが混ざっていたら除去
content = content.replace("```json", "").replace("```", "").strip()
try:
return json.loads(content)
except json.JSONDecodeError:
# シングルクォート等の緩いフォーマットに対するフォールバック
try:
return ast.literal_eval(content)
except:
print(f"Failed to parse JSON: {content[:100]}...")
return []
except Exception as e:
print(f"Error generating QA for chunk: {e}")
return []
def main():
doc_path = "data/remote_work_policy.md"
if not os.path.exists(doc_path):
# ルート/ソース直下から実行した場合のフォールバック
doc_path = "../data/remote_work_policy.md"
if not os.path.exists(doc_path):
print("Error: Document not found.")
return
text = load_data(doc_path)
# 見出し(##)で分割し、各条文を1チャンクとして扱う
sections = text.split("\n## ")
qa_dataset = []
print(f"Found {len(sections)} sections. Generating QA pairs...")
for i, section in enumerate(sections):
if not section.strip(): continue
# (先頭を除き)取り除かれた見出しマーカーを付け直す
# 分割で区切り文字自体は消えるので、内容だけを使う
# ただ、チャンクが何の条文か分かるようにしたい
# 無料枠のレート制限対策(目安: 毎分約15回)。
# 1セクションの処理で外部呼び出しは1回。
# 念のため1秒スリープ。
time.sleep(1)
print(f"Processing section {i+1}...")
pairs = generate_qa_pairs(section)
if isinstance(pairs, dict):
pairs = [pairs]
elif not isinstance(pairs, list):
pairs = []
qa_dataset.extend(pairs)
output_path = "data/synthetic_qa.json"
# ソース直下から実行している場合は出力パスを調整
if not os.path.exists("data") and os.path.exists("../data"):
output_path = "../data/synthetic_qa.json"
with open(output_path, "w", encoding="utf-8") as f:
json.dump(qa_dataset, f, ensure_ascii=False, indent=2)
print(f"Successfully generated {len(qa_dataset)} QA pairs and saved to {output_path}")
if __name__ == "__main__":
main()
# src/rag_system.py
from langchain_community.vectorstores import Chroma
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.documents import Document
import os
class SimpleRAG:
def __init__(self, persist_directory="./chroma_db"):
self.embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
self.llm = ChatGoogleGenerativeAI(model="gemini-3-flash-preview", temperature=0)
self.vectorstore = None
self.persist_directory = persist_directory
def index_documents(self, file_path):
"""マークダウンファイルを読み込み、チャンク化してクローマデータベースにインデックスします。"""
if not os.path.exists(file_path):
raise FileNotFoundError(f"{file_path} not found.")
with open(file_path, "r", encoding="utf-8") as f:
text = f.read()
# コンテキストを保つためのチャンク分割(規定の条文ごと)
# チャンク内で文脈を保つため '##' を付け直す
sections = text.split("\n## ")
docs = []
for s in sections:
content = s.strip()
if not content: continue
if not content.startswith("#"): # 先頭が # でなければ、前文か分割時に削られた可能性がある
content = "## " + content
docs.append(Document(page_content=content, metadata={"source": file_path}))
# ベクトルストアを作成して永続化
self.vectorstore = Chroma.from_documents(
documents=docs,
embedding=self.embeddings,
persist_directory=self.persist_directory
)
# 新しいクローマは自動で永続化するが、明示的にしておいてもよい(または初期化に任せる)
print(f"Indexed {len(docs)} documents into {self.persist_directory}")
def query(self, question):
"""コンテキストを検索し、回答を生成します。"""
if not self.vectorstore:
# 既存データベースを読み込み
self.vectorstore = Chroma(
persist_directory=self.persist_directory,
embedding_function=self.embeddings
)
# 検索(取得)
retriever = self.vectorstore.as_retriever(search_kwargs={"k": 2})
docs = retriever.invoke(question)
context = "\n\n".join([d.page_content for d in docs])
# 生成
prompt = f"""
あなたは社内規定に関する質問に答えるアシスタントです。
以下の「社内規定(コンテキスト)」のみに基づいて、質問に答えてください。
コンテキストに答えが見つからない場合は、「規定に記載がありません」と答えてください。
【コンテキスト】
{context}
【質問】: {question}
"""
response = self.llm.invoke(prompt)
return {
"question": question,
"answer": response.content.strip(),
"context": context,
"source_documents": docs
}
# src/evaluate.py
import json
import os
import time
import pandas as pd
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import ChatPromptTemplate
from dotenv import load_dotenv
from rag_system import SimpleRAG
load_dotenv()
def evaluate_answer(question, truth, prediction, context):
"""
Geminiを使って忠実性と正確性を採点します。
(忠実性スコア, 正確性スコア) を返します。
"""
llm = ChatGoogleGenerativeAI(model="gemini-3-flash-preview", temperature=0.0)
# --- 指標1: 忠実性(ハルシネーションチェック) ---
# 回答はコンテキストのみに基づいているか?
faith_template = """
あなたはRAGシステムの評価者です。
以下の手順で「生成された回答」を評価してください。
タスク: 「生成された回答」が「コンテキスト」に含まれる情報のみに基づいているか判定する。
入力:
- コンテキスト: {context}
- 生成された回答: {prediction}
判定基準:
- コンテキストにある情報だけで回答が構成されていれば 1
- コンテキストにない情報(幻覚や外部知識)が含まれていれば 0
出力:
数字(0 または 1)のみを出力してください。
"""
# --- 指標2: 正確性(正解データとの整合性) ---
# 回答は期待される正解(正解データ)と一致しているか?
correct_template = """
あなたはRAGシステムの評価者です。
「生成された回答」と「正解(Ground Truth)」を比較して、その正確性を評価してください。
入力:
- 質問: {question}
- 正解: {truth}
- 生成された回答: {prediction}
判定基準:
- 生成された回答が、正解の意味内容と一致していれば 1
- 矛盾している、または重要な情報が欠けていれば 0
出力:
数字(0 または 1)のみを出力してください。
"""
try:
faith_prompt = ChatPromptTemplate.from_template(faith_template)
correct_prompt = ChatPromptTemplate.from_template(correct_template)
faith_chain = faith_prompt | llm
correct_chain = correct_prompt | llm
faith_res = faith_chain.invoke({"context": context, "prediction": prediction})
correct_res = correct_chain.invoke({"question": question, "truth": truth, "prediction": prediction})
correct_res = correct_chain.invoke({"question": question, "truth": truth, "prediction": prediction})
# 出力をパース
f_content = faith_res.content
c_content = correct_res.content
if isinstance(f_content, list): f_content = "".join([str(x) for x in f_content])
if isinstance(c_content, list): c_content = "".join([str(x) for x in c_content])
f_score = int(f_content.strip().split('\n')[0].strip())
c_score = int(c_content.strip().split('\n')[0].strip())
return f_score, c_score
except Exception as e:
print(f"Error in evaluation: {e}")
return 0, 0
def main():
# パス設定(ソース直下/ルート実行に対応)
if os.path.exists("data"):
data_dir = "data"
elif os.path.exists("../data"):
data_dir = "../data"
else:
# ゼロから/ソース直下で実行する場合はデータ用ディレクトリを作成
# ただし、ここではデータ用ディレクトリが存在すると仮定。
data_dir = "data"
doc_path = os.path.join(data_dir, "remote_work_policy.md")
qa_path = os.path.join(data_dir, "synthetic_qa.json")
results_path = os.path.join(data_dir, "evaluation_results.csv")
db_path = "./chroma_db" # カレントディレクトリ
print("Initializing RAG System...")
rag = SimpleRAG(persist_directory=db_path)
print("Initializing RAG System...")
rag = SimpleRAG(persist_directory=db_path)
# 再インデックスを避けるためデータベースの存在を確認(クォータ節約)
if os.path.exists(db_path) and os.listdir(db_path):
print(f"Vector DB found at {db_path}, skipping re-indexing.")
else:
print(f"Indexing {doc_path}...")
try:
rag.index_documents(doc_path)
except Exception as e:
print(f"Error indexing: {e}. Waiting 60s to retry...")
time.sleep(60)
rag.index_documents(doc_path)
if not os.path.exists(qa_path):
print(f"QA data not found at {qa_path}. Please run generate_qa.py first.")
return
with open(qa_path, "r", encoding="utf-8") as f:
qa_pairs = json.load(f)
print(f"Starting evaluation of {len(qa_pairs)} questions...")
results = []
for i, item in enumerate(qa_pairs):
q = item["question"]
t = item["answer"]
print(f"\nExample {i+1}: Q: {q}")
# 1. 検索拡張生成を実行
rag_res = rag.query(q)
pred = rag_res["answer"]
ctx = rag_res["context"]
print(f" Prediction: {pred[:50]}...")
# 2. 判定(採点)
f_score, c_score = evaluate_answer(q, t, pred, ctx)
print(f" Scores -> Faithfulness: {f_score}, Correctness: {c_score}")
results.append({
"question": q,
"ground_truth": t,
"prediction": pred,
"context": ctx,
"faithfulness": f_score,
"correctness": c_score
})
# 検索+採点のレート制限対策
print("Sleeping 15s to avoid rate limits...")
time.sleep(15)
# 集計
df = pd.DataFrame(results)
df.to_csv(results_path, index=False)
print("\n" + "="*30)
print("EVALUATION SUMMARY")
print("="*30)
print(f"Total Questions: {len(df)}")
print(f"Faithfulness Rate: {df['faithfulness'].mean():.2f}")
print(f"Correctness Rate: {df['correctness'].mean():.2f}")
print(f"Detailed results saved to {results_path}")
if __name__ == "__main__":
main()







