
記事の要点
- 日々溜まるスクリーンショットをAIが理解し、自動で該当のフォルダに分類するプログラムを作成した。
- 機密情報が外部に漏れないよう、手元のPC内で完全に動作するローカルLLMを採用した。
- Pythonスクリプトと設定ファイルのシンプルな構成で、手軽に導入・カスタマイズ可能とした。
はじめに
こんにちは!株式会社エスタイル AI/データサイエンス事業部で事業部長をしているフィルです。
突然ですが、大量のスクリーンショットの整理や検索に苦労した経験はありませんか?
気付けばデスクトップやフォルダは画像で溢れかえり、「あのエラーメッセージのスクリーンショットはどこだっけ…」「先週のミーティングで撮ったグラフは…」と、画像を探す時間はボディブローのように効いていきます。
この小さなストレスを解決するため、今回は「AIがスクリーンショットを判断し、自動でカテゴリ分けしてくれるプログラム」を開発しました。この記事では、その設計思想から実装、そして実際に動かしたときの感動までをお伝えします。
プログラムの概要
今回作成するプログラムのコンセプトは「シンプル、安全、軽量」です。これを実現するために、main.py、config.yml、 requirements.txtといった3つのファイルだけで構成しました。
本記事ではAIとLLMの表現が混在していますが、AIはプログラム全体、LLMは部品としてのテキスト生成モデルを指すように心掛けています。
main.pyはプログラムの心臓部です。指定されたフォルダを監視し、新しい画像を見つけるとLLMに「これ、どんな画像?」と問いかけます。LLMからの返答を受け取り、適切なフォルダに画像を移動させる役割を担います。バックグラウンドで静かに動き続ける「デーモン」としての機能も持たせました。
config.ymlはこのプログラムをカスタマイズするための設計図です。監視するフォルダの場所、分類したいカテゴリ名(例: code, text)、使用するLLMの種類など、環境や好みによって変える部分をこのファイルで一元管理します。スクリプトを直接書き換える必要がないため、安全かつ手軽に設定を変更できます。
requirements.txtはプログラムを動かすために必要な部品リストです。Pythonに「これらの部品(ライブラリ)を使います」と教えるためのもので、環境構築をスムーズに行う手助けをします。
設計で最もこだわったのは、「LLMの処理を高速化するために画像解像度を小さくする」ようにした点です。そのための工夫が、画像リサイズ処理です。
具体的には、LLMに送信する画像を4分の1の解像度に縮小することで、ローカルLLMの計算負荷を大幅に軽減し、分類処理の速度を向上させました。
一方で、ファイル整理は元のファイルに対して行い、画質の劣化が起きないようにしています。これにより、大量のスクリーンショットを効率的に処理しながら、保存品質は妥協しない仕組みを実現しています。
実装コードの紹介
それでは、実際のコードを見ていきましょう。ここでは全3ファイルの中身を掲載します。
main.py
監視から分類、ファイル移動、ログ出力まで、すべての機能がこのスクリプトに詰まっています。
import os
import json
import base64
import time
from pathlib import Path
from datetime import datetime
import yaml
import requests
from PIL import Image
import io
import atexit
class ScreenshotClassifier:
"""スクリーンショット分類システム"""
def __init__(self, config_path="config.yml"):
# 設定読み込み
with open(config_path, 'r', encoding='utf-8') as f:
self.config = yaml.safe_load(f)
# ディレクトリ設定
self.base_dir = Path(os.path.expanduser(self.config['directory']))
# アプリ・ログディレクトリ(デーモン時のchdir対策として絶対パスで保持)
self.app_dir = Path(__file__).resolve().parent
self.log_dir = Path(self.config.get('log_dir', self.app_dir))
self.log_dir.mkdir(parents=True, exist_ok=True)
# PIDファイルパス
self.pidfile = self.log_dir / "classifier.pid"
# 分類ディレクトリ作成
for label in self.config['labels']:
(self.base_dir / label).mkdir(exist_ok=True)
print(f"監視ディレクトリ: {self.base_dir}")
print(f"PIDファイル: {self.pidfile}")
# ===== Helper methods (DRY) =====
def _read_pid(self):
"""PIDファイルを読み取って返す(存在しない/壊れている場合はNone)"""
try:
if not self.pidfile.exists():
return None
with open(self.pidfile, 'r') as f:
return int(f.read().strip())
except Exception:
return None
def _is_running(self, pid: int) -> bool:
"""PIDが動作中かをチェック"""
try:
os.kill(pid, 0)
return True
except OSError:
return False
def _remove_pidfile(self):
"""PIDファイルを安全に削除"""
try:
if self.pidfile.exists():
self.pidfile.unlink()
except Exception:
pass
def _current_log_path(self) -> Path:
"""当日分のログファイルパス"""
return self.log_dir / f"classifier_{datetime.now().strftime('%Y%m%d')}.log"
def _print_daemon_start_info(self):
"""デーモン開始時の案内出力(DRY)"""
print("バックグラウンド実行開始")
print(f"ログファイル: {self._current_log_path()}")
print(f"PIDファイル: {self.pidfile}")
print(f"停止するには: python {__file__} --stop")
def create_pidfile(self):
"""PIDファイル作成"""
try:
# 既存のプロセスがまだ動いているかチェック
old_pid = self._read_pid()
if old_pid is not None:
if self._is_running(old_pid):
print(f"既にプロセスが実行中です (PID: {old_pid})")
print(f"停止するには: kill {old_pid}")
return False
else:
print(f"古いPIDファイルを削除: {old_pid}")
self._remove_pidfile()
# 新しいPIDファイル作成
current_pid = os.getpid()
with open(self.pidfile, 'w') as f:
f.write(str(current_pid))
# プログラム終了時にPIDファイルを削除
atexit.register(self.cleanup_pidfile)
print(f"PIDファイル作成: {current_pid}")
self.log_message(f"デーモン開始 (PID: {current_pid})")
return True
except Exception as e:
print(f"PIDファイル作成エラー: {e}")
return False
def cleanup_pidfile(self):
"""PIDファイル削除"""
try:
if self.pidfile.exists():
self.pidfile.unlink()
print("PIDファイル削除")
except Exception as e:
print(f"PIDファイル削除エラー: {e}")
def stop_daemon(self):
"""デーモン停止"""
try:
pid = self._read_pid()
if pid is None:
print("PIDファイルが見つかりません")
return False
# プロセス停止
os.kill(pid, 15) # SIGTERM
print(f"プロセス停止信号送信 (PID: {pid})")
# PIDファイル削除
time.sleep(1)
self._remove_pidfile()
print("PIDファイル削除")
return True
except FileNotFoundError:
print("PIDファイルが見つかりません")
return False
except ProcessLookupError:
print("プロセスが見つかりません(既に停止済み)")
# 古いPIDファイルを削除
self._remove_pidfile()
return False
except PermissionError:
print("プロセス停止の権限がありません")
return False
except Exception as e:
print(f"停止エラー: {e}")
return False
def get_status(self):
"""デーモン状態確認"""
try:
if not self.pidfile.exists():
print("デーモンは停止中")
return False
pid = self._read_pid()
if pid is None:
print("デーモンは停止中(PIDファイル不正)")
self._remove_pidfile()
return False
# プロセス存在確認
try:
if self._is_running(pid):
print(f"デーモン実行中 (PID: {pid})")
print(f"停止するには: python {__file__} --stop")
return True
else:
raise OSError
except OSError:
print("デーモンは停止中(古いPIDファイル検出)")
self._remove_pidfile()
return False
except Exception as e:
print(f"状態確認エラー: {e}")
return False
def encode_image(self, image_path):
"""画像を解像度を下げてBase64エンコード"""
try:
# 画像を開く
with Image.open(image_path) as img:
# 解像度を4分の1に縮小
original_size = img.size
new_size = (original_size[0] // 4, original_size[1] // 4)
resized_img = img.resize(new_size, Image.Resampling.LANCZOS)
# Base64エンコード用のバッファに保存
buffer = io.BytesIO()
# 元のフォーマットを保持
format_name = img.format if img.format else 'JPEG'
resized_img.save(buffer, format=format_name)
buffer.seek(0)
return base64.b64encode(buffer.getvalue()).decode('utf-8')
except Exception as e:
print(f"画像リサイズエラー: {e}")
# フォールバック:元の画像をそのまま使用
with open(image_path, 'rb') as f:
return base64.b64encode(f.read()).decode('utf-8')
def classify_image(self, image_path):
"""VLMで画像分類"""
try:
# プロンプト作成
labels_text = ", ".join(self.config['labels'])
system_prompt = f"""画像を以下のカテゴリから1つ選んで分類してください:
{labels_text}
JSON形式で回答してください:
{{"label": "カテゴリ名", "confidence": 0.85}}"""
# Ollama API呼び出し
payload = {
"model": self.config['model'],
"messages": [
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": "この画像を分類してください",
"images": [self.encode_image(image_path)]
}
],
"stream": False
}
response = requests.post(
f"{self.config['api_url']}/chat",
json=payload,
timeout=self.config.get('timeout', 120)
)
response.raise_for_status()
# レスポンス解析
content = response.json()['message']['content']
# JSON抽出
try:
result = json.loads(content)
label = result.get('label', 'others')
# ラベル検証
if label not in self.config['labels']:
label = 'others'
print(f"{image_path.name} → {label}")
return label
except json.JSONDecodeError:
print(f"JSON解析エラー: {image_path.name}")
return 'others'
except Exception as e:
error_msg = self._get_error_message(e, image_path.name)
print(error_msg)
return 'others'
def _get_error_message(self, error, filename):
"""エラーメッセージを生成(DRY)"""
if isinstance(error, requests.exceptions.ConnectionError):
return "API接続エラー: Ollamaが起動していません"
elif isinstance(error, requests.exceptions.Timeout):
return f"タイムアウト: VLMの処理が遅すぎます({self.config.get('timeout', 120)}秒)"
elif isinstance(error, requests.exceptions.RequestException):
if "404" in str(error):
return f"モデルエラー: {self.config['model']}が見つかりません"
else:
return f"API呼び出しエラー: {error}"
else:
return f"分類エラー: {filename} - {error}"
def move_file(self, file_path, label):
"""ファイル移動"""
try:
dest_dir = self.base_dir / label
dest_path = dest_dir / file_path.name
# 同名ファイル対応
counter = 1
while dest_path.exists():
name = file_path.stem
ext = file_path.suffix
dest_path = dest_dir / f"{name}_{counter}{ext}"
counter += 1
file_path.rename(dest_path)
print(f"移動完了: {dest_path}")
return True
except Exception as e:
print(f"移動エラー: {e}")
return False
def get_target_files(self):
"""処理対象ファイル取得"""
files = []
for pattern in self.config['patterns']:
for file in self.base_dir.glob(pattern):
# 分類ディレクトリ内のファイルは除外
if file.is_file() and file.parent == self.base_dir:
files.append(file)
return sorted(files)
def process_files(self, console_output=True):
"""ファイル処理(共通ロジック)"""
files = self.get_target_files()
if not files:
self.log_message("処理対象ファイルなし", console_output)
return 0, 0
batch_size = self.config.get('batch_size', 5)
files_to_process = files[:batch_size]
self.log_message(f"{len(files)}ファイル発見", console_output)
success = 0
for file in files_to_process:
if console_output:
self.log_message(f"処理中: {file.name}", True)
# 分類実行
label = self.classify_image(file)
# ファイル移動
if self.move_file(file, label):
success += 1
time.sleep(0.5) # API負荷軽減
self.log_message(f"処理完了: {success}/{len(files_to_process)}", console_output)
return success, len(files_to_process)
def process_once(self):
"""1回実行"""
self.process_files(console_output=True)
def log_message(self, message, console=False):
"""ログ出力(console=Trueでコンソールにも出力)"""
if console:
print(message)
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
log_file = self._current_log_path()
with open(log_file, 'a', encoding='utf-8') as f:
f.write(f"[{timestamp}] {message}\n")
def process_daemon(self):
"""デーモン実行"""
# PIDファイル作成
if not self.create_pidfile():
return
try:
while True:
try:
self.log_message("実行開始")
self.process_files(console_output=False)
interval = self.config.get('interval', 3600)
self.log_message(f"{interval}秒待機")
time.sleep(interval)
except Exception as e:
self.log_message(f"エラー: {e}")
time.sleep(60) # エラー時は1分待機
except KeyboardInterrupt:
self.log_message("デーモン停止(Ctrl+C)")
except SystemExit:
self.log_message("デーモン停止(SIGTERM)")
finally:
self.cleanup_pidfile()
def main():
"""メイン処理"""
import argparse
parser = argparse.ArgumentParser(description="スクリーンショット自動分類")
parser.add_argument('--daemon', action='store_true', help='バックグラウンド実行')
parser.add_argument('--stop', action='store_true', help='デーモン停止')
parser.add_argument('--status', action='store_true', help='デーモン状態確認')
args = parser.parse_args()
try:
classifier = ScreenshotClassifier()
if args.stop:
# デーモン停止
classifier.stop_daemon()
elif args.status:
# 状態確認
classifier.get_status()
elif args.daemon:
# デーモン(定期実行)モード
try:
# python-daemon がインストールされていればバックグラウンド化
import daemon # type: ignore
import signal
import sys
def signal_handler(signum, frame):
_ = signum, frame # 未使用変数の警告回避
classifier.log_message("デーモン停止")
sys.exit(0)
classifier._print_daemon_start_info()
# デーモン化(作業ディレクトリをアプリ直下に固定し、シグナルをハンドリング)
with daemon.DaemonContext(
working_directory=str(classifier.app_dir),
umask=0o022,
signal_map={
signal.SIGTERM: signal_handler,
signal.SIGINT: signal_handler,
},
):
classifier.process_daemon()
except ImportError:
# フォールバック:python-daemon が無ければフォアグラウンドでループ実行
print("python-daemon未インストールのためフォアグラウンドで定期実行します")
classifier._print_daemon_start_info()
print("停止するには: Ctrl+C")
classifier.process_daemon()
else:
# 1回実行
classifier.process_once()
except FileNotFoundError:
print("config.ymlが見つかりません")
except Exception as e:
print(f"エラー: {e}")
if __name__ == "__main__":
main()
config.yml
このファイルを編集するだけで、プログラムの挙動を自分好みに変えられます。
# スクリーンショット自動分類設定 # 監視ディレクトリ(ホームディレクトリのScreenshotsフォルダ) directory: "~/Desktop" # 処理対象ファイル patterns: - "*.png" # 分類カテゴリ labels: - "text" # テキストのスクリーンショット - "code" # プログラムコード - "chart" # グラフ・チャート - "image" # 写真・イラスト - "others" # その他 # VLMモデル設定 model: "qwen2.5vl:3b" api_url: "http://localhost:11434/api" timeout: 120 # API呼び出しタイムアウト(秒) # 処理設定 batch_size: 5 # 1回に処理するファイル数 interval: 60 # 定期実行間隔(秒)
requirements.txt
外部ライブラリはかなりシンプルです。
pyyaml
requests
python-daemon
pillow注意事項!
本記事で利用したモデルは Qwen2.5-VL 3Bを想定しています。実運用の際は正式なタグ・ライセンスは公式リポジトリで確認してください。
本システムはローカルで完結しますが、モデルに依存した誤分類やプロンプトインジェクション等のリスクは残っています。
プログラムの動かし方
このプログラムを動かすのはとても簡単です。ターミナル(WindowsならコマンドプロンプトやPowerShell)で以下の手順を実行してください。
1. 環境準備とライブラリのインストール
プロジェクト用のフォルダを作り、その中で仮想環境を有効化してから、必要なライブラリをインストールします。これにより、お使いのPC環境を汚さずに済みます。
# 仮想環境を作成
python -m venv .venv
# 仮想環境を有効化 (Mac/Linux)
source .venv/bin/activate
# (Windowsの場合)
# .venv\Scripts\activate
# 必要なライブラリをインストール
pip install -r requirements.txt2. 設定ファイルの編集
config.ymlファイルを開き、directoryの部分を、ご自身のスクリーンショットが保存されているフォルダのパスに書き換えてください。
3.Ollamaの起動
このプログラムは、手元のPCで動くOllamaというAI実行環境を利用します。Ollamaをインストールし、ターミナルで以下のコマンドを実行して、画像認識が得意なAIモデルを起動しておきましょう。
ollama serve qwen2.5vl:3bまずはテストとして、python main.pyを実行してみます。フォルダ内の画像がいくつか分類されれば成功です。
問題なく動くことが確認できたら、python main.py –daemonコマンドでバックグラウンドでの自動実行を開始しましょう。これでもうあなたはスクリーンショットの整理に頭を悩ませる必要はありません。
実行するとログファイルが作成され、このようにログが記録されます。
[2025-09-14 16:43:14] デーモン開始
[2025-09-14 16:43:14] 実行開始
[2025-09-14 16:43:14] 29ファイル発見
[2025-09-14 16:43:26] 処理完了: 5/5
[2025-09-14 16:43:26] 60秒待機
[2025-09-14 16:44:26] 実行開始
[2025-09-14 16:44:26] 24ファイル発見
[2025-09-14 16:44:36] 処理完了: 5/5
[2025-09-14 16:44:36] 60秒待機自動実行を終了したいときはpython main.py –stopを実行します。
実際に動かしてみた
百聞は一見に如かず。このプログラムがどれだけスマートに機能するのか、実際の動きを見てみましょう。

実行前:混沌としたデスクトップ
これが多くの人の現実ではないでしょうか。ファイル名だけでは中身が分からず、目的の画像を探す気力も失せそうな、雑然としたデスクトップです。
このフォルダに対してpython main.pyを実行すると、ターミナル上で次々と処理が進んでいきます。そして、先ほどのフォルダは…

実行後: ファイルはすべて新しく作られたカテゴリ別フォルダに整理されました。
見事にカテゴリ別のフォルダに自動で整理されました! LLMが画像の内容をしっかりと理解し、適切に分類してくれているのが分かります。
codeフォルダとtextフォルダの中身を見てみましょう。
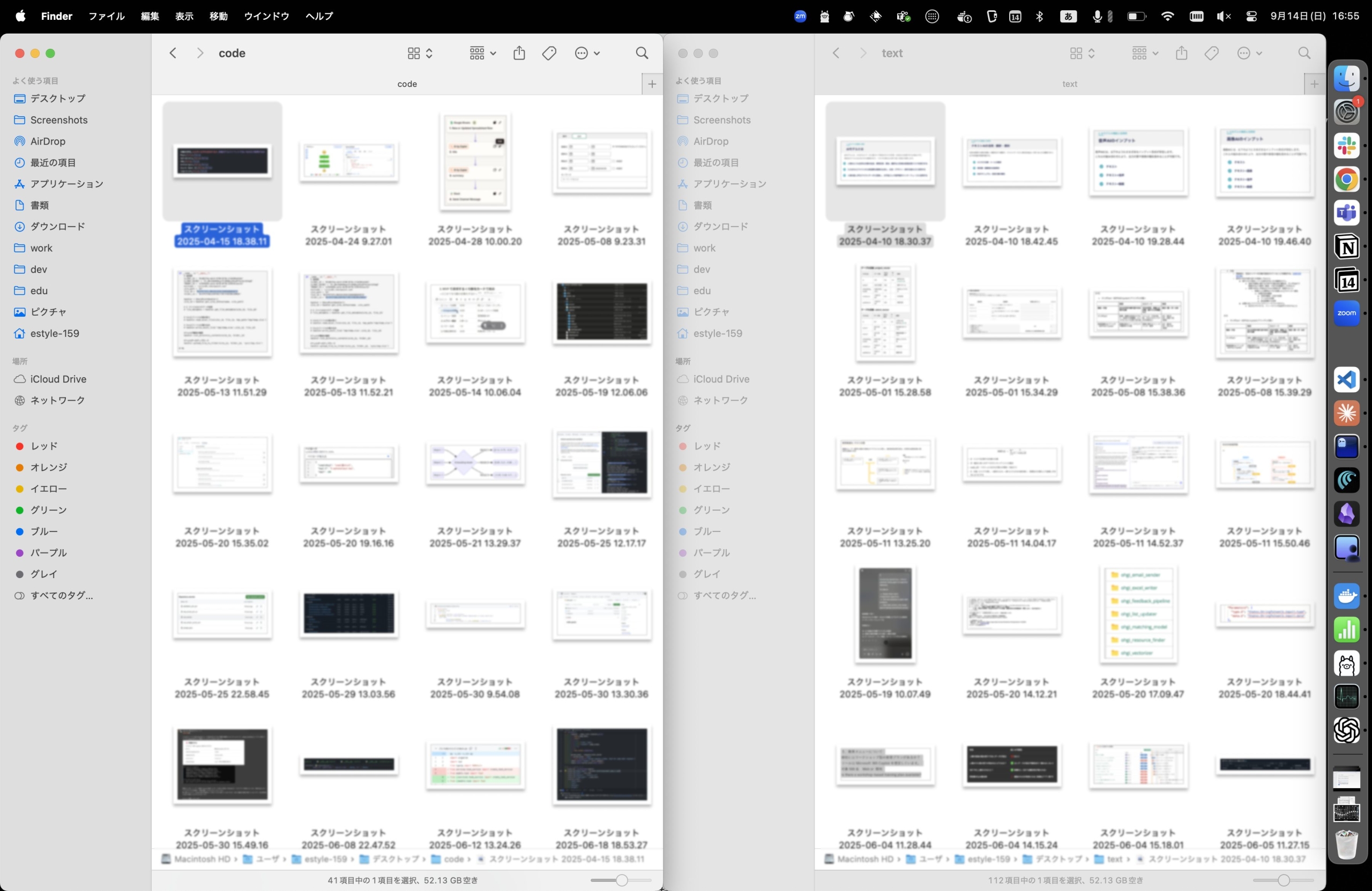
codeフォルダとtextフォルダの例(機密情報があるためボカしをかけています)
見事にソースコードとテキストを分類することができています。
今回、AlibabaのQwen2.5-VL 3BというローカルPCでも動作可能な軽量モデルを使用しましたが、十分実用的でとても驚きました。
AI活用の課題の一つにセキュリティがありますが、ローカルLLMなら処理がPC内で完結するため安心です。
これからローカルLLMを使ったユースケースを探索していきたいと思います!
まとめ
今回は、ローカルLLMを使って、スクリーンショットの自動整理プログラムを作成しました。
「こんな面倒な作業があるなら、プログラムで自動化できないか?」と考えることが、エンジニアリングの第一歩です。この記事が、あなたの「やってみたい!」という気持ちを刺激し、プログラミングの楽しさを感じるきっかけになれば、これ以上嬉しいことはありません。
ぜひ、config.ymlのlabelsを自分流にカスタマイズして、あなただけの整理プログラムにしてみてください!
参考文献
API Reference – Ollama English Documentation
Unlocking the Future of AI with Qwen 2.5 VL: Where Vision Meets Language – Alibaba Cloud Community







