
記事の要点
- Markdownの日記をBigQueryとLooker Studioで可視化するパイプラインを構築した。
- BigQuery とGeminiを連携させ、日記の内容から「翌日の行動指針」や「週末のプラン」をAIに自動提案させる機能を実装した。
- iPhoneのショートカット機能を使用し、クラウドにデータを送信する機能を実装した。
はじめに
株式会社エスタイルのハーランドです。
いきなりですが、皆さんは睡眠記録や日記をつけていますでしょうか?
エンジニアの方であれば、日々の生活習慣やメモをデータとして残している方も多いかもしれません。これらの記録をつける中で、「日々の生活データをもっと有効活用できたら、より充実した毎日を送れるのではないか」と思ったことはありませんか?
自分の日々の調子や生活習慣の乱れを示す指標が可視化され、ひと目で確認できたらカッコいいですよね。今回は、そんな「可視化」と、Geminiによる「ネクストアクションの提案」を組み合わせた、自分だけの生活管理ツールを作成しました。
「日記を書いているけれど、読み返す習慣がない」「自分の体調変化をデータで把握したい」といった悩みを持っている方の参考になれば幸いです。
開発の背景
私は普段、日記をMarkdownファイルで記入しています。
Markdown形式のノート同士を相互にリンクで繋げることができる「Obsidian」というツールで、以下のようなフォーマットで編集し、iCloudストレージ上に保存しています。
日記例.md
# 生活記録
## 記録
+ 睡眠時刻: 24:00
+ 起床時刻: 7:30
- 朝(8:30)の元気度: 55
- 自己採点: 60
## 身につけたい習慣
* [ ] 朝_5分ストレッチ
- [x] 風呂後_5分ストレッチ
# 日記部分
## 今日やろうとしたことと出来たこと。
新しい決済APIの連携タスクを完了させることができた。
ただ、次のプロジェクトの企画書作成は導入部分のアイデア出しで時間を使ってしまい、清書までは手がつけられなかった。
## 備忘録(未来の自分が読み返した時に参考になるもの。あれば)
〇〇ライブラリを使う際は、非同期処理の競合を防ぐため必ずトランザクション処理を加えることを忘れない。テストデータ作成にはダミーデータのジェネレーターツールを使うと効率が良い。
## (可能なら書く)明日の予定
- 何時に寝たいか:0:30
- 予定何があるか:チーム内での進捗確認会と、午後からは新しいフレームワークの自己学習時間を確保する。
## 良かったこと(うまくいったこと、感動したこと、嬉しかったこと)
懸念していた機能のデプロイが無事に完了し、ユーザーからの動作報告も好調だった。ランチで食べた新しいラーメン屋の限定メニューが想像以上に美味しかった。
## 良くなかったこと(うまくいかなかったこと・嫌だったこと)(あれば)
終業間際に顧客から急な仕様変更の依頼があり、対応方針を考えるのに時間を取られてしまった。帰宅途中の電車が遅延していて、少し疲れてしまった。
## 土日にやりたいこと(あれば)
金曜の夜はサウナに行ってリフレッシュしたい。土曜日は友人とフットサルをする予定が入っているので、体を動かしたい。
--- 日記区切り線 ---
1日1日の情報は確認できる一方、長期的な傾向(「睡眠時間が減ると元気度が下がるのではないか」など)を把握するのが困難でした。
そこで、「前日の日記データを手動でBigQueryにアップロードし、テーブルとして保存・生活記録をLooker Studioで可視化」する仕組みを作ることにしました。
さらに、単なる数値のグラフ化だけでなく、同一ファイルに含まれる「日記」のテキストデータを活用し、「今日の注意点や週末の予定をGeminiに提案させる」機能も実装しました。
実装方針
今回の実装では、完全な自動化(定時バッチ実行など)ではなく、あえて手動アップロードを採用しています。私の日々の日記のつけ方として、「翌日の朝に、前日の内容を追記・修正する」ということが多々発生するため、自分のタイミングで確定データを送信できる手動実行を選択しました。
また、朝の通勤移動中にデータを確認することが多いため、PCを開かずにiPhoneのショートカットから処理を実行し、その場で可視化結果を確認できることを必須要件としました。
システムの全体像は以下の通りです。
【処理フロー】
- Input:iPhone上のMarkdownファイル(iCloud管理)
- Action:iPhoneの「ショートカット」アプリからAPIを実行
- Process(Cloud Run):Python (FastAPI) でMarkdownを解析・抽出
- Data Warehouse(BigQuery):抽出データを保存 & GeminiによるAI分析を実行
- 可視化(Looker Studio):データをグラフ化し、Web/モバイルで閲覧
図は下記のようになります。
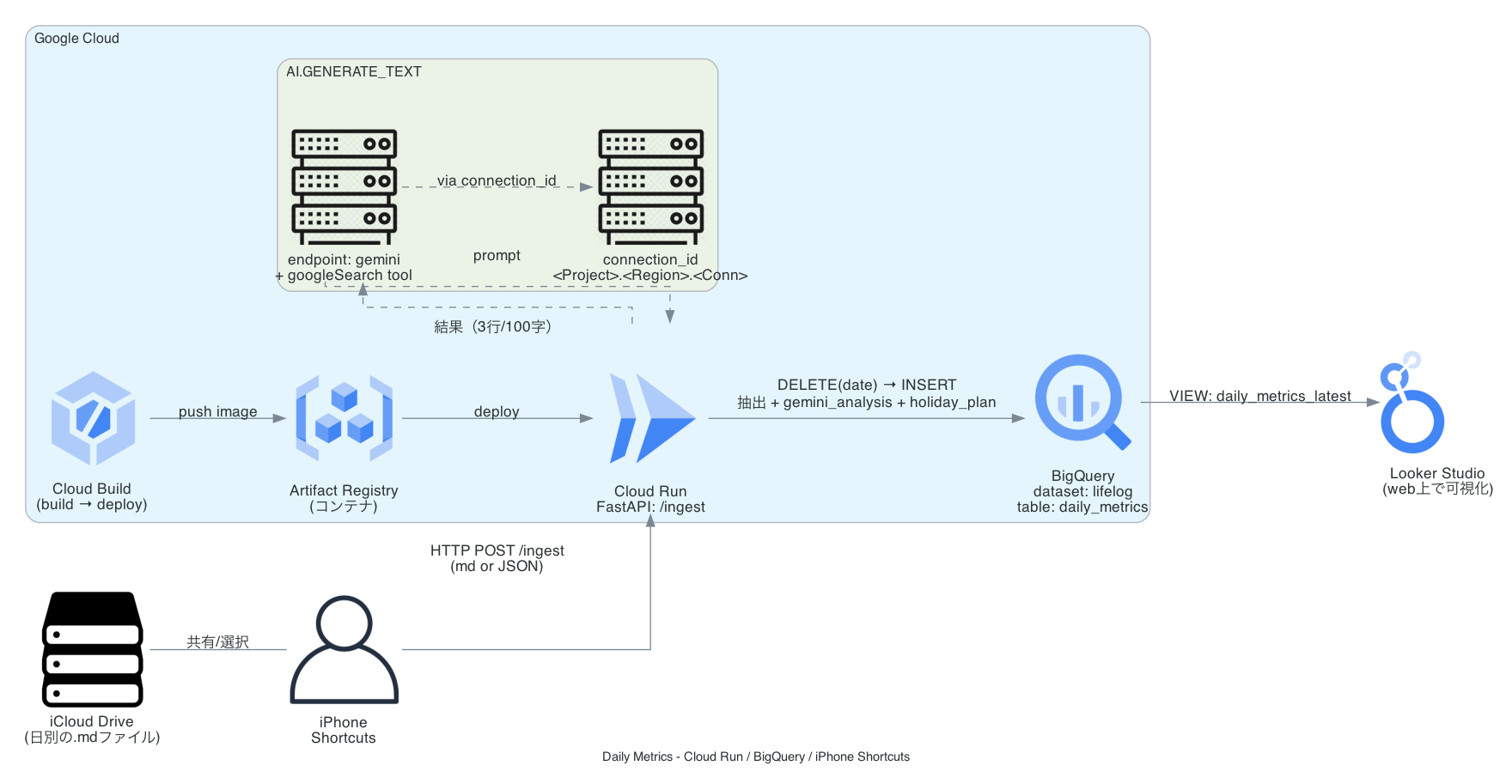
サーバーレスでコストを抑えつつPythonを実行できる Google Cloud Run と、データの蓄積・分析・AI連携が一気通貫で行える BigQuery を採用しました。
実装
iPhoneでダッシュボードを確認できる事を目的として、次の3段階で実装を行いました。
- 日記の内容をBigQueryにデータとして追加するスクリプトおよびiPhoneショートカットの作成
- BigQueryでのGemini実装
- Looker Studioによる可視化
1. 日記の内容をBigQueryにデータとして追加するスクリプトおよびiPhoneショートカットの作成
まずは、非構造化データであるMarkdownの日記ファイルを、分析可能な構造化データとしてクラウドへアップロードする基盤を作成しました。
Markdown抽出ロジック(Cloud Run / Python)
Markdownファイルからは、次の情報を取得することを目指します。
「就寝時間」
「睡眠時間」
「朝の元気度」
「1日の自己採点」
「習慣記録」
「日記原文」
これらを正規表現を使って抽出し、数値データに変換するAPIをFastAPIで構築しました。
main_old.py
# main_old.py
# FastAPI on Cloud Run: iPhoneのショートカットから受け取ったMarkdownを抽出→BigQueryにUpsert(原文は保持しない)
#
# 【仕様概要】
# - 入力: Markdownテキスト(ファイルまたはJSON)
# - 出力: BigQueryへのデータ保存(既存日付は削除して再挿入)
# - 日付決定の優先順位: ①ファイル名(YYYY-MM-DD) → ②明示指定(date) → ③本文内日付 → ④JSTの“前日”
#
# 【主な取得項目】
# - 睡眠データ(就寝・起床・睡眠時間)
# - 「朝_5分ストレッチ」→ moning_strech (1:実施 / 0:未実施)
# - 「風呂後ストレッチ」→ after_bath_strech (1:実施 / 0:未実施)
# - 「# 日記 … --- 日記区切り線 ---」を diary_raw へ保存(テンプレのみの場合はNULL)
import os
import re
import logging
from datetime import datetime, timedelta
from typing import Optional
from fastapi import FastAPI, UploadFile, File, Form
from fastapi.responses import JSONResponse
from pydantic import BaseModel
from google.cloud import bigquery
# FastAPIインスタンスの作成
app = FastAPI(title="Daily Metrics Ingest API")
# 環境変数から設定を読み込む
PROJECT = os.environ.get("PROJECT")
DATASET = os.environ.get("BQ_DATASET", "lifelog")
TABLE = os.environ.get("BQ_TABLE", "daily_metrics")
if not PROJECT:
logging.warning("Environment variable PROJECT is not set. BigQuery operations will fail.")
# BigQueryのテーブル参照パスを作成
TABLE_REF = f"{PROJECT}.{DATASET}.{TABLE}" if PROJECT else None
# -------------------------
# Regexes / Helpers (正規表現とヘルパー関数)
# -------------------------
# 日付抽出用の正規表現 (YYYY-MM-DD)
FILENAME_DATE_RE = re.compile(r"(20\d{2}-\d{2}-\d{2})")
BODY_DATE_RE = re.compile(r"(20\d{2}-\d{2}-\d{2})")
# チェックボックス判定用の正規表現
# [x], [X], [✓] などのマークを検出する
CHECKED_STRETCH_MORNING_RE = re.compile(r"^[\-\*\+]\s*\[(x|X|✓|✔)\]\s*朝[_\s]?5分ストレッチ\s*$", re.MULTILINE)
CHECKED_STRETCH_BATH_RE = re.compile(r"^[\-\*\+]\s*\[(x|X|✓|✔)\]\s*風呂[_\s]?後[_\s]?ストレッチ\s*$", re.MULTILINE)
# 日記ブロック抽出用の正規表現
DIARY_START_RE = re.compile(r"^#\s*日記\s*$", re.MULTILINE)
DIARY_END_RE = re.compile(r"^---\s*日記区切り線\s*---\s*$", re.MULTILINE)
# 追記なし(テンプレートのまま)か判定するためのプレースホルダ文字列
PLACEHOLDER_LINES = {"a", "tmp", "hh:mm"}
def jst_now() -> datetime:
"""現在時刻をJST(UTC+9)で取得"""
return datetime.utcnow() + timedelta(hours=9)
def default_date_str() -> str:
"""日付指定がない場合のデフォルト値(JSTでの前日)を返す"""
return (jst_now() - timedelta(days=1)).strftime("%Y-%m-%d")
def extract_date_from_filename(name: Optional[str]) -> Optional[str]:
"""ファイル名から日付文字列を抽出する"""
if not name:
return None
base = os.path.basename(name)
m = FILENAME_DATE_RE.search(base)
return m.group(1) if m else None
def ensure_table_and_columns(bq: bigquery.Client):
"""
BigQueryテーブルの初期化処理。
テーブルが存在しない場合は作成し、列が不足している場合は追加する(スキーママイグレーション)。
"""
base_schema = [
bigquery.SchemaField("date", "DATE"),
bigquery.SchemaField("yesterday_score", "INT64"),
bigquery.SchemaField("morning_genkido", "INT64"),
bigquery.SchemaField("sleep_start", "STRING"),
bigquery.SchemaField("wake_time", "STRING"),
bigquery.SchemaField("sleep_duration_hours", "FLOAT64"),
bigquery.SchemaField("moning_strech", "INT64"), # 朝ストレッチ有無
bigquery.SchemaField("after_bath_strech", "INT64"), # 風呂後ストレッチ有無
bigquery.SchemaField("diary_raw", "STRING"), # 日記原文
]
try:
table = bq.get_table(TABLE_REF)
existing = {f.name.lower(): f for f in table.schema}
for f in base_schema:
if f.name.lower() not in existing:
logging.info(f"Adding missing column: {f.name} {f.field_type}")
# 不足しているカラムを追加
bq.query(f"ALTER TABLE `{TABLE_REF}` ADD COLUMN {f.name} {f.field_type}").result()
except Exception:
# テーブル自体がない場合は新規作成
bq.create_table(bigquery.Table(TABLE_REF, schema=base_schema))
def _ex(pattern: str, text: str) -> Optional[str]:
"""正規表現でマッチした最初のグループの文字列を抽出するヘルパー"""
m = re.search(pattern, text, flags=re.MULTILINE)
return m.group(1).strip() if m else None
def decide_date(source_filename: Optional[str], explicit_date: Optional[str], body_text: str) -> str:
"""
データの対象日付を決定する。
優先順位: ①ファイル名 → ②リクエストパラメータ → ③本文内の記載 → ④デフォルト(前日)
"""
d1 = extract_date_from_filename(source_filename)
if d1:
return d1
if explicit_date:
return explicit_date
m = BODY_DATE_RE.search(body_text)
if m:
return m.group(1)
return default_date_str()
def detect_moning_strech(md_text: str) -> int:
"""朝のストレッチがチェックされているか判定(1: Yes, 0: No)"""
return 1 if CHECKED_STRETCH_MORNING_RE.search(md_text) else 0
def detect_after_bath_strech(md_text: str) -> int:
"""風呂後のストレッチがチェックされているか判定(1: Yes, 0: No)"""
return 1 if CHECKED_STRETCH_BATH_RE.search(md_text) else 0
def extract_diary_block(md_text: str) -> Optional[str]:
"""「# 日記」から「--- 日記区切り線 ---」までのテキストブロックを抽出"""
s = DIARY_START_RE.search(md_text)
e = DIARY_END_RE.search(md_text)
if not s or not e or e.start() <= s.end(): return None return md_text[s.end():e.start()].strip() # 既存のプレースホルダ定義 # PLACEHOLDER_LINES = {"a", "tmp", "hh:mm"} はそのまま利用 # テンプレート判定用の定数定義 TEMPLATE_HEADING_RE = re.compile(r"^##\s*\(可能なら書く\)明日の予定\s*$") TEMPLATE_IMAGE_LINE = "イメージ:月・水・土・日は23時代/ 火・木・金は1時まで起床など" # テンプレートの各プロンプト(末尾の全角コロンがデフォルト) TEMPLATE_PROMPTS = [ "何時に起きるか:", "何時に寝たいか:", "どうやって勉強時間を達成するか, 夕飯・風呂との兼ね合いをどうするか:", ] def is_template_prompt_line(line: str) -> bool:
"""
行が未記入のテンプレート(箇条書き)かどうかを判定する。
例: "* 何時に起きるか:" の後ろに何も書かれていなければTrue
"""
t = line.strip()
if not t.startswith("*"):
return False
# 先頭の "* " を外す
t = t.lstrip("*").strip()
for p in TEMPLATE_PROMPTS:
# 「プロンプトそのまま」か、コロン後に空白のみ → テンプレ扱い
if t == p or t.startswith(p + " "):
# コロン以降に有意味文字がなければテンプレ
rest = t[len(p):].strip()
return len(rest) == 0
return False
def normalize_diary_for_null_check(text: str) -> str:
"""
日記の内容が実質的に空(テンプレートのみ)かどうかを判定するために正規化を行う。
不要な行(見出し、空行、説明書き)を除去したテキストを返す。
"""
if not text:
return ""
cleaned_lines = []
for line in text.splitlines():
raw = line.rstrip("\n")
t = raw.strip()
if not t: # 空行
continue
if t.startswith("#"): # 見出し
# 特に「## (可能なら書く)明日の予定」は明示的に除去
if TEMPLATE_HEADING_RE.match(t):
continue
# それ以外の見出しも除外(従来仕様)
continue
if t in PLACEHOLDER_LINES: # 簡易プレースホルダ
continue
if t == TEMPLATE_IMAGE_LINE: # イメージ既定行(そのままなら除外)
continue
if is_template_prompt_line(t): # 箇条書きテンプレ(未記入)
continue
# ここまで残った行は“有意味”な記述とみなす
cleaned_lines.append(t)
return "\n".join(cleaned_lines).strip()
def parse_md(md_text: str, explicit_date: Optional[str] = None, source_filename: Optional[str] = None):
"""
Markdownテキストを解析し、BigQueryへ格納する辞書形式のデータを生成するメインロジック。
"""
# 1. 日付の決定
date_str = decide_date(source_filename, explicit_date, md_text)
# 2. 各種メトリクスの抽出(正規表現)
yesterday_score = _ex(r"昨日の採点:\s*([0-9]+)", md_text)
morning_genkido = _ex(r"朝\([0-9:ー\-〜~]*\)の元気度:\s*([0-9]+)", md_text)
sleep_start = _ex(r"睡眠時刻:\s*([0-9]{1,2}:[0-9]{2})", md_text)
wake_time = _ex(r"起床時刻:\s*([0-9]{1,2}:[0-9]{2})", md_text)
# 3. 睡眠時間(h)の計算(日跨ぎ対応)
sleep_duration_hours = None
try:
if sleep_start and wake_time:
sh, sm = map(int, sleep_start.split(":"))
wh, wm = map(int, wake_time.split(":"))
s = sh + sm / 60
w = wh + wm / 60
# 18時以降の就寝、または就寝時刻が起床時刻より大きい場合は日跨ぎと判定
dur = (24 - s) + w if (sh >= 18 or s > w) else (w - s)
sleep_duration_hours = round(dur, 2)
except Exception:
logging.exception("sleep duration calculation failed")
# 4. 習慣フラグの抽出
moning_strech = detect_moning_strech(md_text)
after_bath_strech = detect_after_bath_strech(md_text)
# 5. 日記本文の抽出と保存判定
diary_block = extract_diary_block(md_text)
diary_raw: Optional[str] = None
if diary_block is not None:
payload = normalize_diary_for_null_check(diary_block)
# 「実質追記なし」判定:残った文字数が5文字未満なら未保存扱い
if payload and len(payload.replace("\n", "").strip()) >= 5:
diary_raw = diary_block # 原文をそのまま保存
return {
"date": date_str,
"yesterday_score": int(yesterday_score) if yesterday_score else None,
"morning_genkido": int(morning_genkido) if morning_genkido else None,
"sleep_start": sleep_start,
"wake_time": wake_time,
"sleep_duration_hours": sleep_duration_hours,
"moning_strech": moning_strech,
"after_bath_strech": after_bath_strech,
"diary_raw": diary_raw, # 全文 or NULL
}
def upsert_row(row: dict) -> dict:
"""
BigQueryへのデータ登録処理。
重複を防ぐため、同一日付のデータが存在する場合は削除してから挿入する(Delete-Insert方式)。
"""
bq = bigquery.Client(project=PROJECT)
ensure_table_and_columns(bq)
# 同一日付のデータを削除
bq.query(
f"DELETE FROM `{TABLE_REF}` WHERE date = @d",
job_config=bigquery.QueryJobConfig(
query_parameters=[bigquery.ScalarQueryParameter("d", "DATE", row["date"])]
),
).result()
# 新しいデータを挿入
errors = bq.insert_rows_json(TABLE_REF, [row])
if errors:
raise RuntimeError(str(errors))
return row
# -------------------------
# Models
# -------------------------
class JsonPayload(BaseModel):
"""JSON入力時のリクエストボディ定義"""
date: Optional[str] = None
yesterday_score: Optional[int] = None
morning_genkido: Optional[int] = None
sleep_start: Optional[str] = None
wake_time: Optional[str] = None
markdown_raw: Optional[str] = None
source_filename: Optional[str] = None
# -------------------------
# Endpoints
# -------------------------
@app.get("/health")
def health():
"""ヘルスチェック用エンドポイント"""
return {"ok": True, "time_jst": jst_now().isoformat()}
@app.post("/ingest/file")
async def ingest_file(file: UploadFile = File(...), date: Optional[str] = Form(None)):
"""
Markdownファイルアップロード用エンドポイント
推奨:iPhoneショートカットからmdファイルをPOST。
date未指定の場合はファイル名から日付を推測します。
"""
try:
content = await file.read()
md = content.decode("utf-8", errors="ignore")
# 解析処理
row = parse_md(md, explicit_date=date, source_filename=file.filename)
# DB保存処理
saved = upsert_row(row)
return {"ok": True, "row": saved}
except Exception as e:
logging.exception("ingest_file failed")
return JSONResponse({"ok": False, "error": str(e)}, status_code=500)
@app.post("/ingest/json")
def ingest_json(payload: JsonPayload):
"""
JSONデータ投入用エンドポイント
すでに解析済みのデータや、テストデータ投入に使用可能。
"""
try:
if payload.markdown_raw:
# Markdownが含まれる場合はパース処理を通す
row = parse_md(
payload.markdown_raw,
explicit_date=payload.date,
source_filename=payload.source_filename
)
else:
# 各フィールドが個別に指定されている場合
date_from_name = extract_date_from_filename(payload.source_filename) if payload.source_filename else None
date_val = date_from_name or payload.date or default_date_str()
row = {
"date": date_val,
"yesterday_score": payload.yesterday_score,
"morning_genkido": payload.morning_genkido,
"sleep_start": payload.sleep_start,
"wake_time": payload.wake_time,
"sleep_duration_hours": None,
"moning_strech": 0,
"after_bath_strech": 0,
"diary_raw": None,
}
saved = upsert_row(row)
return {"ok": True, "row": saved}
except Exception as e:
logging.exception("ingest_json failed")
return JSONResponse({"ok": False, "error": str(e)}, status_code=500)iPhoneショートカットからの連携
このAPIを呼び出すトリガーとして、iPhone標準の「ショートカット」アプリを使用しました。
「共有シート」からMarkdownファイルを選択し、Cloud RunのエンドポイントへHTTP POSTするだけのシンプルなショートカットを作成することで、PCを開かずにデータのアップロードが可能になりました。
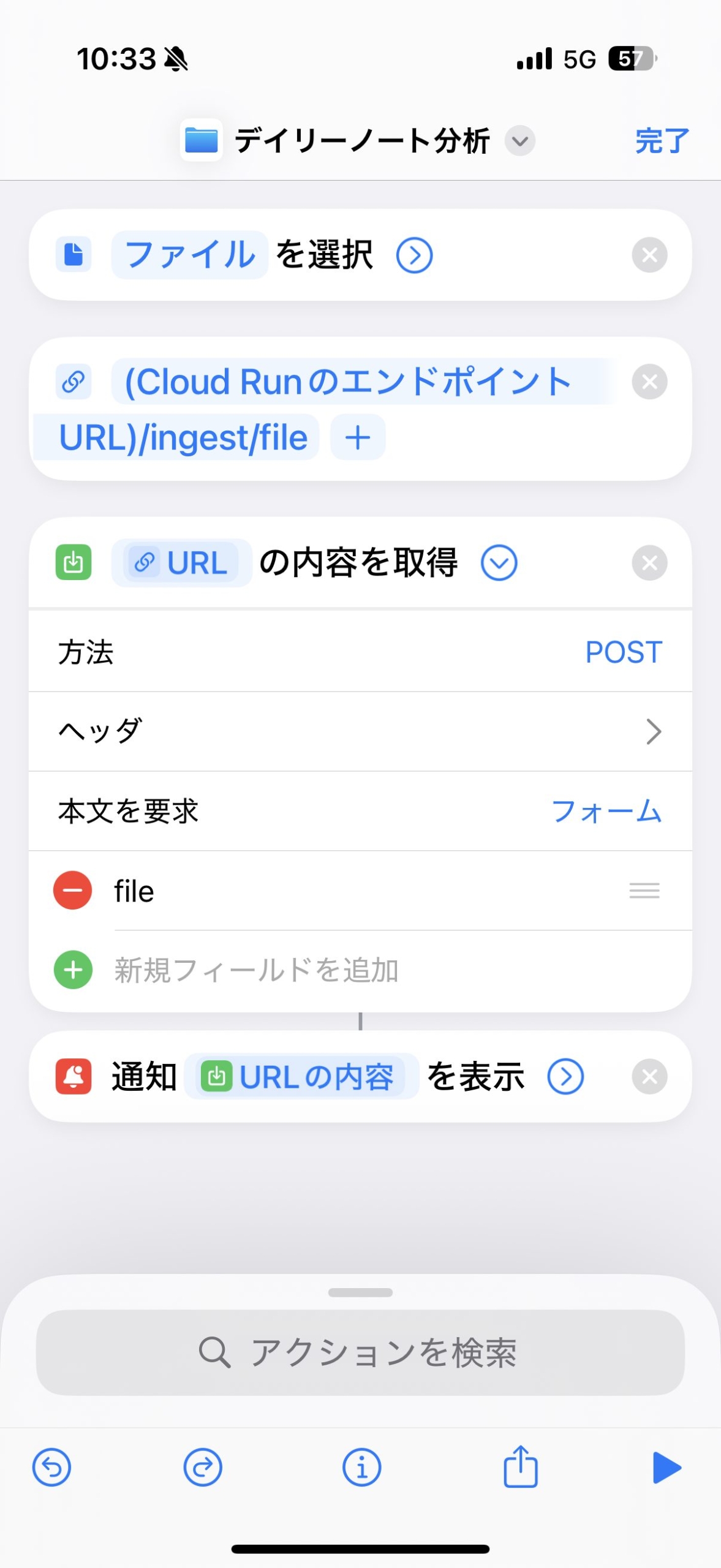
問題なく送信できると、下記のように通知がでます。
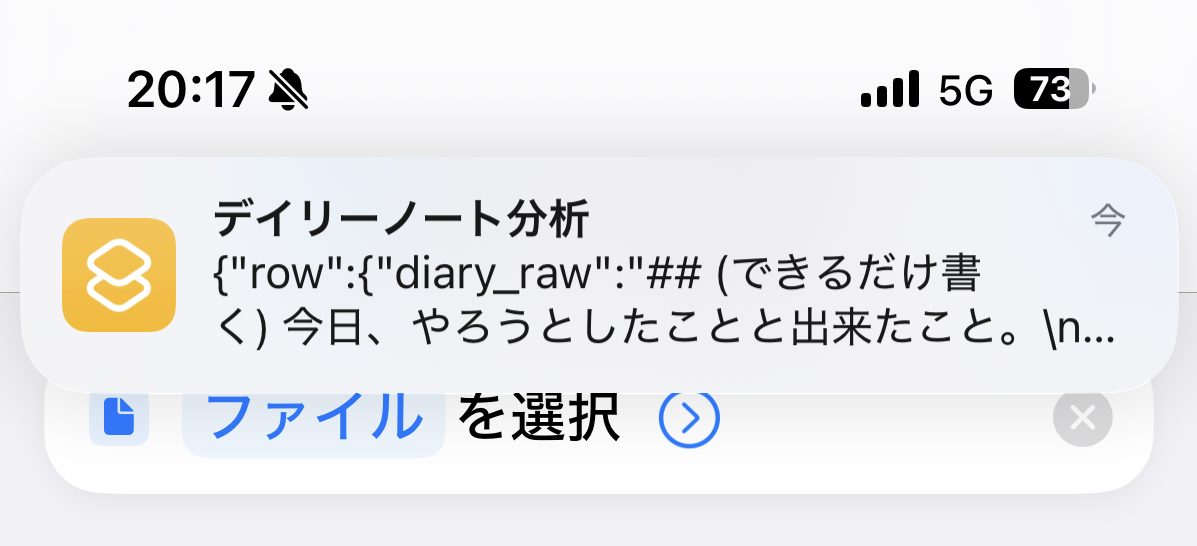
この時点でBigQueryのテーブルを確認すると、意図したレコードが入力されていることが確認できます。
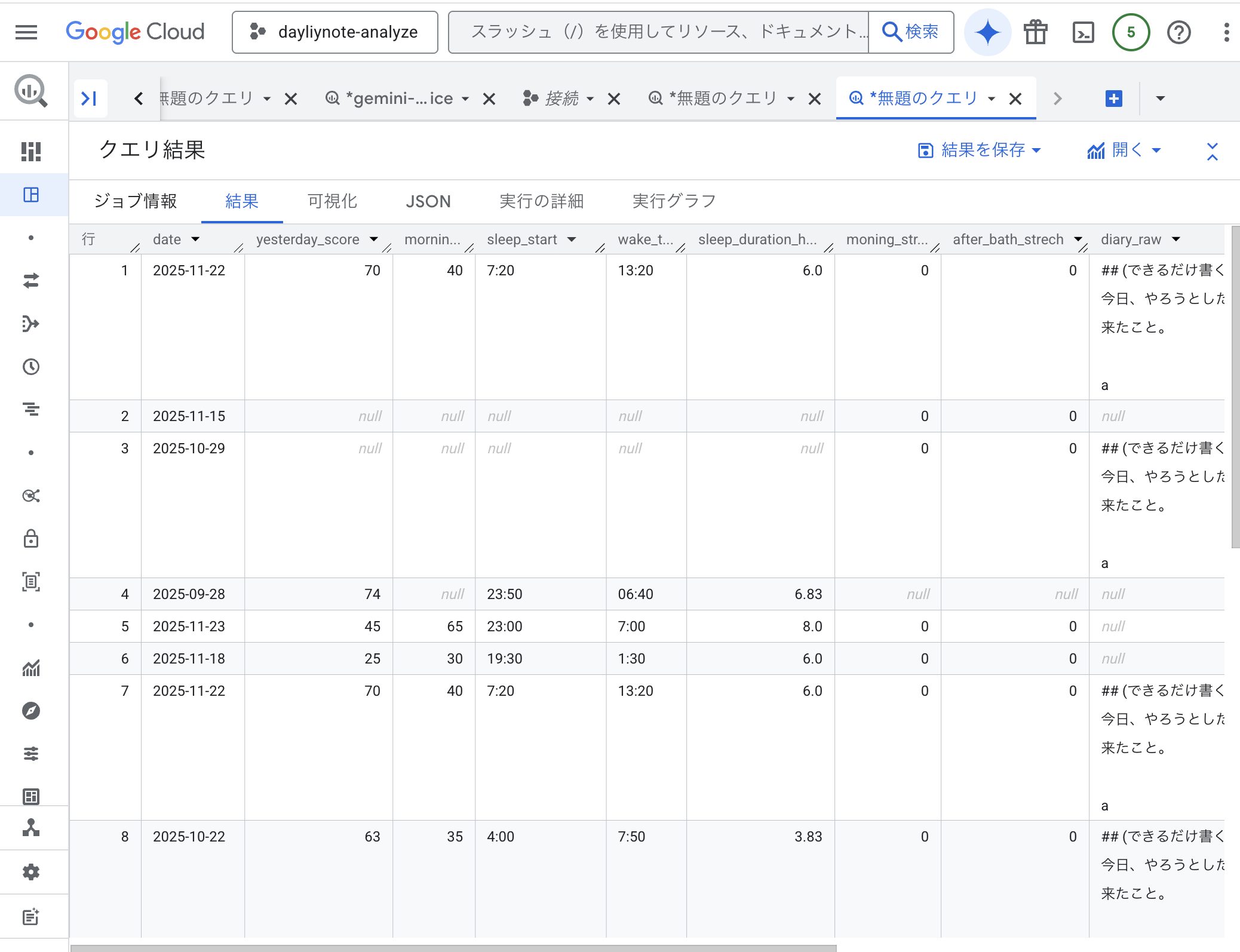
テーブル結果抜粋
2. BigQueryでのGemini実装
データが蓄積されるようになったので、次にBigQuery内でGeminiを呼び出し、日記の内容から「ネクストアクション」や「週末のプラン」を自動提案させる機能を実装しました。
リモートモデルの事前設定
実装に入る前の準備として、BigQueryからVertex AIのモデル(Gemini)を利用するための「リモートモデル」を作成する必要があります。 具体的には、BigQuery上で外部接続(Connection)を作成し、以下のデータ定義言語(DDL)を実行してモデルを登録します。
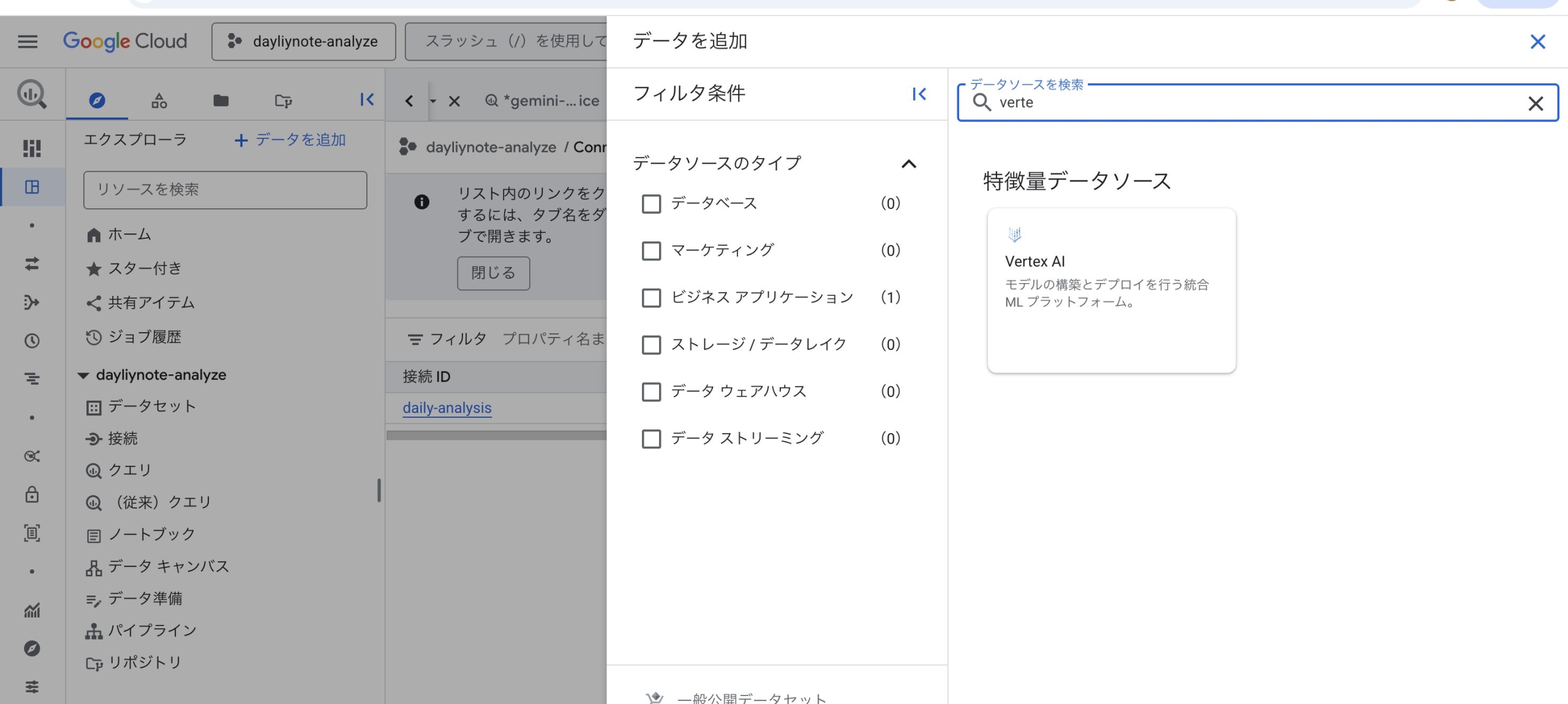
外部接続は、エクスプローラの「データを追加」から「Vertex AI」を選択して追加します。
モデル登録用クエリSQL
-- リモートモデル作成のDDL例
CREATE OR REPLACE MODEL `project.dataset.gemini_remote`
REMOTE WITH CONNECTION `project.region.connection_id`
-- 外部接続で作成したidを使用
OPTIONS (
ENDPOINT = 'gemini-2.5-flash' -- 使用したいモデルを指定
);
このワンステップを踏むことで、SQL関数としてGeminiを呼び出せるようになります。
BigQueryによるAI連携
アプリケーション側でLLM APIを呼び出すのではなく、BigQueryに搭載されているAI.GENERATE_TEXT関数を使用しました。これにより、他のカラムの情報をソースとしてテキスト生成を実行できます。
日記の原文が入ったraw_diaryカラムをデータソースに、以下2つのクエリを追加しています。
1. 明日へのアドバイスを生成するクエリ (run_gemini_on_diaryで定義)
2. 土日にやりたいことが記載されている場合はそれに沿ったプラン・なければおすすめの休日を考えてくれるクエリ(run_holiday_plan)
特に「土日のプラン提案」においては、ground_with_google_search オプションを有効にしました。これにより、実在するスポットや最新情報に基づいた提案が可能になります。
全体コードは下記の通りです。
main.py
# main.py
# FastAPI on Cloud Run:
#
# 【仕様概要】
# - 入力: Markdownデータ
# - 処理フロー:
# 1. Markdown解析と構造化データ抽出
# 2. Gemini (Vertex AI) による日記分析とテキスト生成
# 3. BigQueryへのデータ保存(追記モード)
#
# 【AI生成機能 (AI.GENERATE_TEXT)】
# - diary_raw が存在する場合、以下の2つをSQL関数経由で生成してカラムに保存します。
# 1) gemini_analysis: 明日のアドバイスなど(3行・各1文)
# 2) holiday_plan: 土日の希望に基づいた、Google検索付きの週末プラン提案
#
# 【データ整合性戦略】
# - 更新競合(ストリーミングバッファ制約)を回避するため、DELETEを行わず常にINSERT(追記)します。
# - 利用側(View)で `ingested_at` が最新のレコードを採用する想定です。
import os
import re
import time
import logging
from datetime import datetime, timedelta
from typing import Optional
from fastapi import FastAPI, UploadFile, File, Form
from fastapi.responses import JSONResponse
from pydantic import BaseModel
from google.cloud import bigquery
from google.api_core.exceptions import BadRequest
app = FastAPI(title="Daily Metrics Ingest API (overwrite + AI.GENERATE + google_search)")
# ===== 環境変数 =====
PROJECT = os.environ.get("PROJECT")
DATASET = os.environ.get("BQ_DATASET", "lifelog")
TABLE = os.environ.get("BQ_TABLE", "daily_metrics")
BQ_LOCATION = os.environ.get("BQ_LOCATION", "asia-northeast1") # AI.GENERATE を実行するリージョン
GENAI_MODEL = os.environ["GENAI_MODEL"] # 使用するGeminiモデル名
if not PROJECT:
logging.warning("Environment variable PROJECT is not set. BigQuery operations will fail.")
TABLE_REF = f"{PROJECT}.{DATASET}.{TABLE}" if PROJECT else None
# ===== 正規表現 =====
FILENAME_DATE_RE = re.compile(r"(20\d{2}-\d{2}-\d{2})")
BODY_DATE_RE = re.compile(r"(20\d{2}-\d{2}-\d{2})")
# チェック検出(- [x] ...)
CHECKED_STRETCH_MORNING_RE = re.compile(r"^[\-\*\+]\s*\[(x|X|✓|✔)\]\s*朝[_\s]?5分ストレッチ\s*$", re.MULTILINE)
CHECKED_STRETCH_BATH_RE = re.compile(r"^[\-\*\+]\s*\[(x|X|✓|✔)\]\s*風呂[_\s]?後[_\s]?ストレッチ\s*$", re.MULTILINE)
# 日記抽出
DIARY_START_RE = re.compile(r"^#\s*日記\s*$", re.MULTILINE)
DIARY_END_RE = re.compile(r"^---\s*日記区切り線\s*---\s*$", re.MULTILINE)
# 「土日にやりたいこと」抽出(見出し/行単独/本文内のラベルに対応)
WEEKEND_WISH_HEADING_RE = re.compile(r"^\s*#{1,6}\s*土日(?:に)?やりたいこと\s*$", re.MULTILINE)
WEEKEND_WISH_INLINE_RE = re.compile(r"土日(?:に)?やりたいこと\s*[::]\s*(.+)", re.IGNORECASE)
# 日記テンプレ判定(テンプレだけは未記入扱い)
PLACEHOLDER_LINES = {"a", "tmp", "hh:mm"}
TEMPLATE_HEADING_RE = re.compile(r"^##\s*\(可能なら書く\)明日の予定\s*$")
TEMPLATE_IMAGE_LINE = "イメージ:月・水・土・日は23時代/ 火・木・金は1時まで起床など"
TEMPLATE_PROMPTS = [
"何時に起きるか:",
"何時に寝たいか:",
"どうやって勉強時間を達成するか, 夕飯・風呂との兼ね合いをどうするか:",
]
# ===== ヘルパ =====
def bq_client() -> bigquery.Client:
"""BigQueryクライアントを生成(リージョン指定あり)"""
return bigquery.Client(project=PROJECT, location=BQ_LOCATION)
def jst_now() -> datetime:
"""現在時刻をJST(UTC+9)で取得"""
return datetime.utcnow() + timedelta(hours=9)
def default_date_str() -> str:
"""デフォルト日付(JST前日)"""
return (jst_now() - timedelta(days=1)).strftime("%Y-%m-%d")
def extract_date_from_filename(name: Optional[str]) -> Optional[str]:
"""ファイル名から日付文字列を抽出"""
if not name:
return None
m = FILENAME_DATE_RE.search(os.path.basename(name))
return m.group(1) if m else None
def _ex(pattern: str, text: str) -> Optional[str]:
"""正規表現抽出ヘルパー"""
m = re.search(pattern, text, flags=re.MULTILINE)
return m.group(1).strip() if m else None
def decide_date(source_filename: Optional[str], explicit_date: Optional[str], body_text: str) -> str:
"""日付の決定ロジック:ファイル名 > 明示指定 > 本文 > デフォルト"""
d1 = extract_date_from_filename(source_filename)
if d1:
return d1
if explicit_date:
return explicit_date
m = BODY_DATE_RE.search(body_text)
if m:
return m.group(1)
return default_date_str()
def is_template_prompt_line(line: str) -> bool:
"""箇条書きテンプレート行が未記入かどうかを判定"""
t = line.strip()
if not t.startswith("*"):
return False
t = t.lstrip("*").strip()
for p in TEMPLATE_PROMPTS:
if t == p or t.startswith(p + " "):
rest = t[len(p):].strip()
return len(rest) == 0
return False
def normalize_diary_for_null_check(text: str) -> str:
"""日記テキストからテンプレート記述を除去し、実質的な入力内容のみにする"""
if not text:
return ""
cleaned_lines = []
for raw in text.splitlines():
t = raw.strip()
if not t:
continue
if t.startswith("#"):
if TEMPLATE_HEADING_RE.match(t):
continue
continue
if t in PLACEHOLDER_LINES:
continue
if t == TEMPLATE_IMAGE_LINE:
continue
if is_template_prompt_line(t):
continue
cleaned_lines.append(t)
return "\n".join(cleaned_lines).strip()
def extract_diary_block(md_text: str) -> Optional[str]:
"""日記ブロックの切り出し"""
s = DIARY_START_RE.search(md_text)
e = DIARY_END_RE.search(md_text)
if not s or not e or e.start() <= s.end(): return None return md_text[s.end():e.start()].strip() def detect_moning_strech(md_text: str) -> int:
"""朝ストレッチの実施判定"""
return 1 if CHECKED_STRETCH_MORNING_RE.search(md_text) else 0
def detect_after_bath_strech(md_text: str) -> int:
"""夜ストレッチの実施判定"""
return 1 if CHECKED_STRETCH_BATH_RE.search(md_text) else 0
def extract_weekend_wishes(diary_text: str) -> Optional[str]:
"""
日記本文から「土日にやりたいこと」を抽出。
- 見出し「# 土日にやりたいこと」〜 次の見出し/区切りまで
- または「土日にやりたいこと: xxx」形式の行
"""
if not diary_text:
return None
# 見出しブロック
m = WEEKEND_WISH_HEADING_RE.search(diary_text)
if m:
# 次の見出し or 区切り線 までを抽出
rest = diary_text[m.end():]
end_blocks = list(re.finditer(r"^\s*#{1,6}\s|\n---\s*日記区切り線\s*---", rest, flags=re.MULTILINE))
end_pos = end_blocks[0].start() if end_blocks else len(rest)
block = rest[:end_pos].strip()
block = re.sub(r"^[\-\*\+]\s*", "", block, flags=re.MULTILINE) # 先頭の箇条書き記号除去
return block if block else None
# インライン「…: …」形式
m2 = WEEKEND_WISH_INLINE_RE.search(diary_text)
if m2:
return m2.group(1).strip()
return None
# ===== スキーマ確保 =====
def ensure_table_and_columns(bq: bigquery.Client):
"""
テーブル作成&必要列の存在チェック。欠けていれば ADD COLUMN で追加。
Gemini生成結果用のカラム(gemini_analysis, holiday_plan)もここで定義。
"""
base_schema = [
bigquery.SchemaField("date", "DATE"),
bigquery.SchemaField("yesterday_score", "INT64"),
bigquery.SchemaField("morning_genkido", "INT64"),
bigquery.SchemaField("sleep_start", "STRING"),
bigquery.SchemaField("wake_time", "STRING"),
bigquery.SchemaField("sleep_duration_hours", "FLOAT64"),
bigquery.SchemaField("moning_strech", "INT64"),
bigquery.SchemaField("after_bath_strech", "INT64"),
bigquery.SchemaField("diary_raw", "STRING"),
bigquery.SchemaField("gemini_analysis", "STRING"),
bigquery.SchemaField("holiday_plan", "STRING"), # ★ 追加
]
try:
table = bq.get_table(TABLE_REF)
existing = {f.name.lower(): f for f in table.schema}
for f in base_schema:
if f.name.lower() not in existing:
logging.info("Adding missing column: %s %s", f.name, f.field_type)
bq.query(f"ALTER TABLE `{TABLE_REF}` ADD COLUMN {f.name} {f.field_type}").result()
except Exception:
bq.create_table(bigquery.Table(TABLE_REF, schema=base_schema))
# ===== AI.GENERATE 呼び出し(gemini_analysis) =====
def run_gemini_on_diary(diary_text: str) -> str:
"""
日記の内容をもとにGeminiへ問い合わせ、翌日のアドバイスを生成する。
1) 業務上の意識
2) 生活での注意点
3) 応援の一言
を各1文で生成。
"""
client = bq_client()
model_qualified = f"`{GENAI_MODEL}`" # `project.dataset.model` 形式
# BigQuery MLの AI.GENERATE_TEXT 関数をSQL経由で呼び出す
sql = f"""
WITH req AS (
SELECT CONCAT(
'次の個人日記を読み、以下を各1文で日本語で出力してください。箇条書きや記号は不要。\\n',
'1) 明日、業務上で意識した方がいいこと\\n',
'2) 明日、生活で注意した方がいいこと\\n',
'3) 明日を頑張るための一言\\n',
'\\n--- 日記 ---\\n',
@diary
) AS prompt
)
SELECT
result AS gemini_text
FROM AI.GENERATE_TEXT(
MODEL {model_qualified},
(SELECT prompt FROM req),
STRUCT(0.2 AS temperature, 3000 AS max_output_tokens)
)
"""
cfg = bigquery.QueryJobConfig(
query_parameters=[bigquery.ScalarQueryParameter("diary", "STRING", diary_text or "")]
)
job = client.query(sql, job_config=cfg)
row = next(job.result(max_results=1))
return row["gemini_text"]
def run_holiday_plan(diary_text: str) -> str:
"""
「土日にやりたいこと」があればそれをヒントに、なければおすすめの休日プランを生成する。
特徴: Google検索グラウンディング (ground_with_google_search) を有効化し、
実在するスポットや最新情報に基づいた提案を行う。
"""
client = bq_client()
model_qualified = f"`{GENAI_MODEL}`"
hint = extract_weekend_wishes(diary_text) or ""
sql = f"""
WITH req AS (
SELECT CONCAT(
'次の個人日記を参照し、「土日にやりたいこと」があればそれに沿って、',
'無ければ都内でテンションが上がる休日プランを、100文字程度で日本語出力してください。\\n',
'検索を活用して根拠を補強してください。箇条書きや記号は不要。\\n',
CASE WHEN @hint IS NULL OR @hint = '' THEN '' ELSE CONCAT('ヒント: ', @hint, '\\n') END,
'\\n--- 日記 ---\\n',
@diary
) AS prompt
)
SELECT
result AS holiday_plan
FROM AI.GENERATE_TEXT(
MODEL {model_qualified},
(SELECT prompt FROM req),
STRUCT(0.4 AS temperature, 4000 AS max_output_tokens,TRUE AS ground_with_google_search)
)
"""
cfg = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("diary", "STRING", diary_text or ""),
bigquery.ScalarQueryParameter("hint", "STRING", hint),
]
)
job = client.query(sql, job_config=cfg)
row = next(job.result(max_results=1))
return row["holiday_plan"]
# ===== Markdown 抽出 =====
def parse_md(md_text: str, explicit_date: Optional[str] = None, source_filename: Optional[str] = None) -> dict:
"""Markdown本文を解析し、DB格納用辞書に変換する"""
date_str = decide_date(source_filename, explicit_date, md_text)
yesterday_score = _ex(r"昨日の採点:\s*([0-9]+)", md_text)
morning_genkido = _ex(r"朝\([0-9:ー\-〜~]*\)の元気度:\s*([0-9]+)", md_text)
sleep_start = _ex(r"睡眠時刻:\s*([0-9]{1,2}:[0-9]{2})", md_text)
wake_time = _ex(r"起床時刻:\s*([0-9]{1,2}:[0-9]{2})", md_text)
# 睡眠時間(h) 日跨ぎ対応
sleep_duration_hours = None
try:
if sleep_start and wake_time:
sh, sm = map(int, sleep_start.split(":"))
wh, wm = map(int, wake_time.split(":"))
s = sh + sm / 60
w = wh + wm / 60
dur = (24 - s) + w if (sh >= 18 or s > w) else (w - s)
sleep_duration_hours = round(dur, 2)
except Exception:
logging.exception("sleep duration calculation failed")
# フラグ
moning_strech = detect_moning_strech(md_text)
after_bath_strech = detect_after_bath_strech(md_text)
# 日記抽出(テンプレのみなら NULL 扱い)
diary_block = extract_diary_block(md_text)
diary_raw: Optional[str] = None
if diary_block is not None:
payload = normalize_diary_for_null_check(diary_block)
if payload and len(payload.replace("\n", "").strip()) >= 5:
diary_raw = diary_block
return {
"date": date_str,
"yesterday_score": int(yesterday_score) if yesterday_score else None,
"morning_genkido": int(morning_genkido) if morning_genkido else None,
"sleep_start": sleep_start,
"wake_time": wake_time,
"sleep_duration_hours": sleep_duration_hours,
"moning_strech": moning_strech,
"after_bath_strech": after_bath_strech,
"diary_raw": diary_raw,
"gemini_analysis": None,
"holiday_plan": None, # ★ 後で生成
}
# ===== 上書き(DELETE→INSERT with retry) =====
def delete_by_date_with_retry(bq: bigquery.Client, date_str: str, max_attempts: int = 18, wait_seconds: int = 10):
"""
ストリーミングバッファ(Streaming Buffer)の影響でDELETEが失敗する場合のリトライ処理。
最大約3分待機します。
"""
attempt = 1
while True:
try:
bq.query(
f"DELETE FROM `{TABLE_REF}` WHERE date = @d",
job_config=bigquery.QueryJobConfig(
query_parameters=[bigquery.ScalarQueryParameter("d", "DATE", date_str)]
)
).result()
return
except BadRequest as e:
msg = str(e)
if "would affect rows in the streaming buffer" in msg and attempt < max_attempts: logging.info("Streaming buffer in effect. Retry %d/%d after %ds ...", attempt, max_attempts, wait_seconds) time.sleep(wait_seconds) attempt += 1 continue raise def overwrite_row(row: dict) -> dict:
"""
データをBigQueryに登録する。
以前はDELETE+INSERTを行っていたが、ストリーミングバッファ制約によるエラーを回避するため、
単純なINSERT(追記)に変更。重複排除は分析時のView側で行う設計。
"""
bq = bigquery.Client(project=PROJECT)
ensure_table_and_columns(bq) # スキーマ同期
# ---- AI生成ロジック (変更なし) ----
if row.get("diary_raw"):
try:
# 日記があればGemini分析を実行
ga = run_gemini_on_diary(row["diary_raw"])
if ga:
row["gemini_analysis"] = ga
except Exception:
logging.exception("gemini_analysis generation skipped due to error")
try:
# 日記があれば休日プラン生成(ヒントあり)
hp = run_holiday_plan(row["diary_raw"])
if hp:
row["holiday_plan"] = hp
except Exception:
logging.exception("holiday_plan generation skipped due to error")
else:
try:
# 日記がなくても休日プラン生成(ヒントなし)
hp = run_holiday_plan(None)
if hp:
row["holiday_plan"] = hp
except Exception:
logging.exception("holiday_plan generation skipped due to error")
# ---- INSERT (追記) に変更 ----
# ingested_at に現在時刻(UTC)をセットし、後で最新レコードを判別できるようにする
row["ingested_at"] = datetime.utcnow().isoformat()
sql = f"""
INSERT INTO `{TABLE_REF}` (
date,
yesterday_score,
morning_genkido,
sleep_start,
wake_time,
sleep_duration_hours,
moning_strech,
after_bath_strech,
diary_raw,
gemini_analysis,
holiday_plan,
ingested_at
)
VALUES (
@date,
@yesterday_score,
@morning_genkido,
@sleep_start,
@wake_time,
@sleep_duration_hours,
@moning_strech,
@after_bath_strech,
@diary_raw,
@gemini_analysis,
@holiday_plan,
@ingested_at
)
"""
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("date", "DATE", row["date"]),
bigquery.ScalarQueryParameter("yesterday_score", "INT64", row.get("yesterday_score")),
bigquery.ScalarQueryParameter("morning_genkido", "INT64", row.get("morning_genkido")),
bigquery.ScalarQueryParameter("sleep_start", "STRING", row.get("sleep_start")),
bigquery.ScalarQueryParameter("wake_time", "STRING", row.get("wake_time")),
bigquery.ScalarQueryParameter("sleep_duration_hours", "FLOAT64", row.get("sleep_duration_hours")),
bigquery.ScalarQueryParameter("moning_strech", "INT64", row.get("moning_strech")),
bigquery.ScalarQueryParameter("after_bath_strech", "INT64", row.get("after_bath_strech")),
bigquery.ScalarQueryParameter("diary_raw", "STRING", row.get("diary_raw")),
bigquery.ScalarQueryParameter("gemini_analysis", "STRING", row.get("gemini_analysis")),
bigquery.ScalarQueryParameter("holiday_plan", "STRING", row.get("holiday_plan")),
# Timestamp型パラメータ
bigquery.ScalarQueryParameter("ingested_at", "TIMESTAMP", row["ingested_at"]),
]
)
bq.query(sql, job_config=job_config).result()
return row
# ===== リクエストモデル =====
class JsonPayload(BaseModel):
date: Optional[str] = None
yesterday_score: Optional[int] = None
morning_genkido: Optional[int] = None
sleep_start: Optional[str] = None
wake_time: Optional[str] = None
markdown_raw: Optional[str] = None
# ===== エンドポイント =====
@app.get("/health")
def health():
return {"ok": True, "time_jst": jst_now().isoformat()}
@app.post("/ingest/file")
async def ingest_file(file: UploadFile = File(...), date: Optional[str] = Form(None)):
"""
ファイルアップロード用エンドポイント
推奨:iPhoneショートカットから md をPOST。
日付はファイル名優先(列には保持しません)。
"""
try:
content = await file.read()
md = content.decode("utf-8", errors="ignore")
row = parse_md(md, explicit_date=date, source_filename=file.filename)
saved = overwrite_row(row)
return {"ok": True, "row": saved}
except Exception as e:
logging.exception("ingest_file failed")
return JSONResponse({"ok": False, "error": str(e)}, status_code=500)
@app.post("/ingest/json")
def ingest_json(payload: JsonPayload):
"""
JSON投入も可。dateの明示が無ければ本文から/最終的に既定(JST前日)。
"""
try:
if payload.markdown_raw:
row = parse_md(payload.markdown_raw, explicit_date=payload.date, source_filename=None)
else:
date_val = payload.date or default_date_str()
row = {
"date": date_val,
"yesterday_score": payload.yesterday_score,
"morning_genkido": payload.morning_genkido,
"sleep_start": payload.sleep_start,
"wake_time": payload.wake_time,
"sleep_duration_hours": None,
"moning_strech": 0,
"after_bath_strech": 0,
"diary_raw": None,
"gemini_analysis": None,
"holiday_plan": None,
}
saved = overwrite_row(row)
return {"ok": True, "row": saved}
except Exception as e:
logging.exception("ingest_json failed")
return JSONResponse({"ok": False, "error": str(e)}, status_code=500)
実行結果は下記の画像のようになります。
gemini_analysisカラムとholiday_planカラムが追加されていることがわかります。
holiday_planを見る限り、実行時点だとGeminiはかなりチームラボ推しですね。
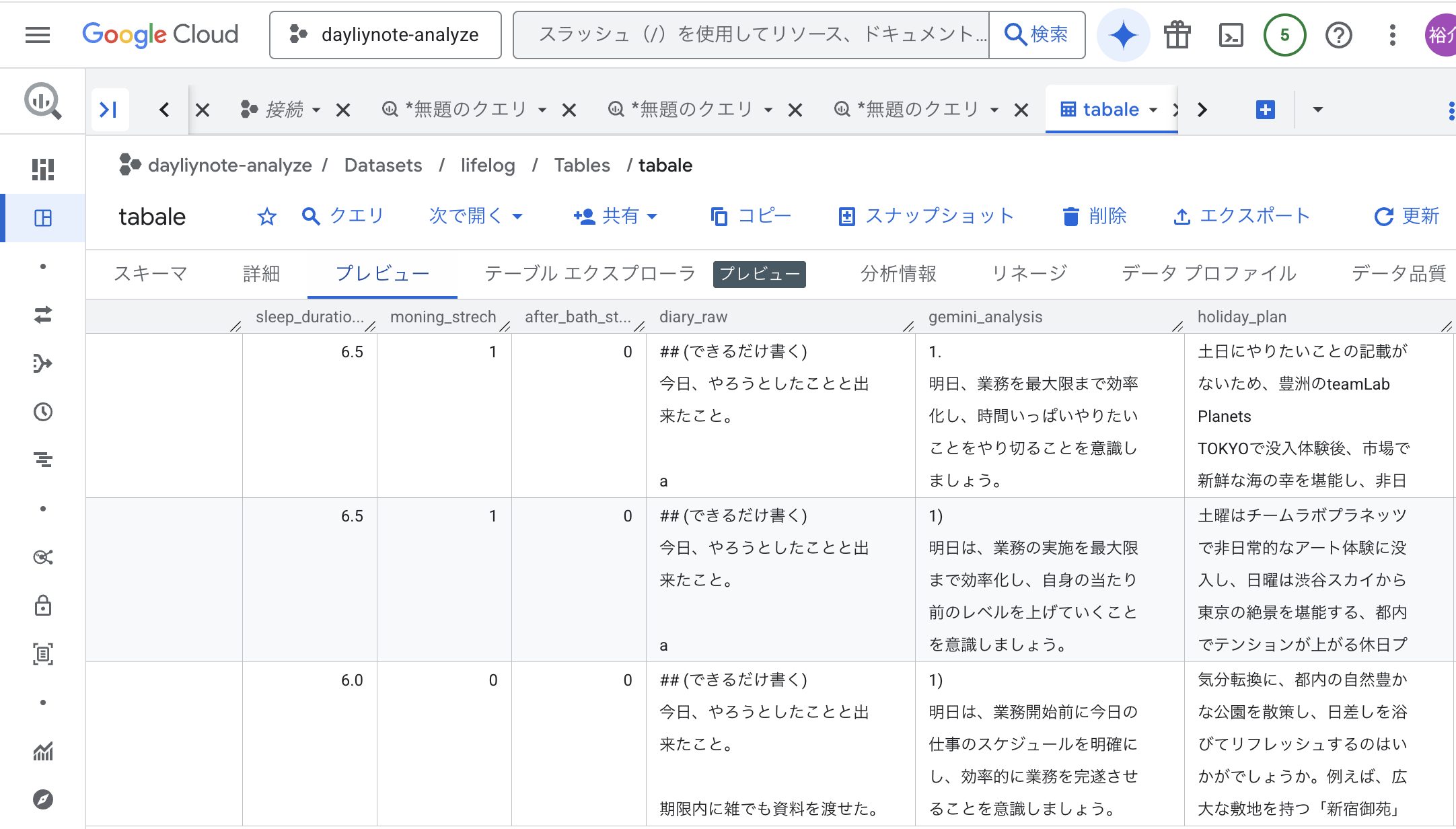
3. Looker Studioによる可視化
最後に、蓄積・生成されたデータを可視化します。
最新データのビュー作成
現状のスクリプトではデータは追記され続けるため、そのまま可視化すると同じ日付のデータが重複してしまいます。そこで、BigQuery上で「各日付ごとに、最も新しい ingested_at を持つ行」のみを抽出するビュー(View)を作成しました。
また、習慣づけを行いたい朝夕のストレッチ情報について、ウインドウズ関数を組み込むことで、連続実施記録を追加できるようにしました。
SQL
WITH raw_data AS (
-- 1. 最新データの特定(変更なし)
SELECT
* EXCEPT(rn)
FROM (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY date ORDER BY ingested_at DESC) as rn
FROM
`dayliynote-analyze.lifelog.daily_metrics`
)
WHERE rn = 1
),
grouped_data AS (
SELECT
*,
-- 【朝】「0(やらなかった日)」までの累積回数でグループ分け
COUNTIF(morning_stretch = 0) OVER (ORDER BY date) AS streak_group_morning,
-- 【夜】同様にグループ分け
COUNTIF(after_bath_stretch = 0) OVER (ORDER BY date) AS streak_group_night
FROM
raw_data
)
SELECT
* EXCEPT(streak_group_morning, streak_group_night),
-- 【朝】連続カウント算出
CASE
WHEN morning_stretch = 0 THEN 0
ELSE ROW_NUMBER() OVER (PARTITION BY streak_group_morning ORDER BY date)
END AS stretch_streak_morning,
-- 【夜】連続カウント算出
CASE
WHEN after_bath_stretch = 0 THEN 0
ELSE ROW_NUMBER() OVER (PARTITION BY streak_group_night ORDER BY date)
END AS stretch_streak_night
FROM
grouped_dataダッシュボードの構築
Looker Studioでは、このビューをデータソースとして作成しました。
iPhoneの縦長画面で見やすいレイアウトを意識し、以下の要素を配置しました。
- スコアカード(4つ):「自己採点」「元気度」の平均値、習慣付けしたい「朝夕ストレッチ」の連続実施記録が表示されるようにしました。 自己採点と元気度は70点を目標に、ストレッチは30日連続を目標にしています。 1日の気合いを入れるために、大きめの文字でシンプルに記載しています。
- 時系列グラフ:直近1週間の「自己採点」推移を記載しています。経験則的に点数が大きく変動している時は体調が悪くなる予兆なので、目安として置いています。
- 表の抜粋(2つ):日記の内容をベースにGeminiが生成した「明日のアドバイス」と「週末のプラン」をそれぞれ表示しています。好みの回答にはまだまだですが、アドバイスしてくれる存在は意外と嬉しいです。
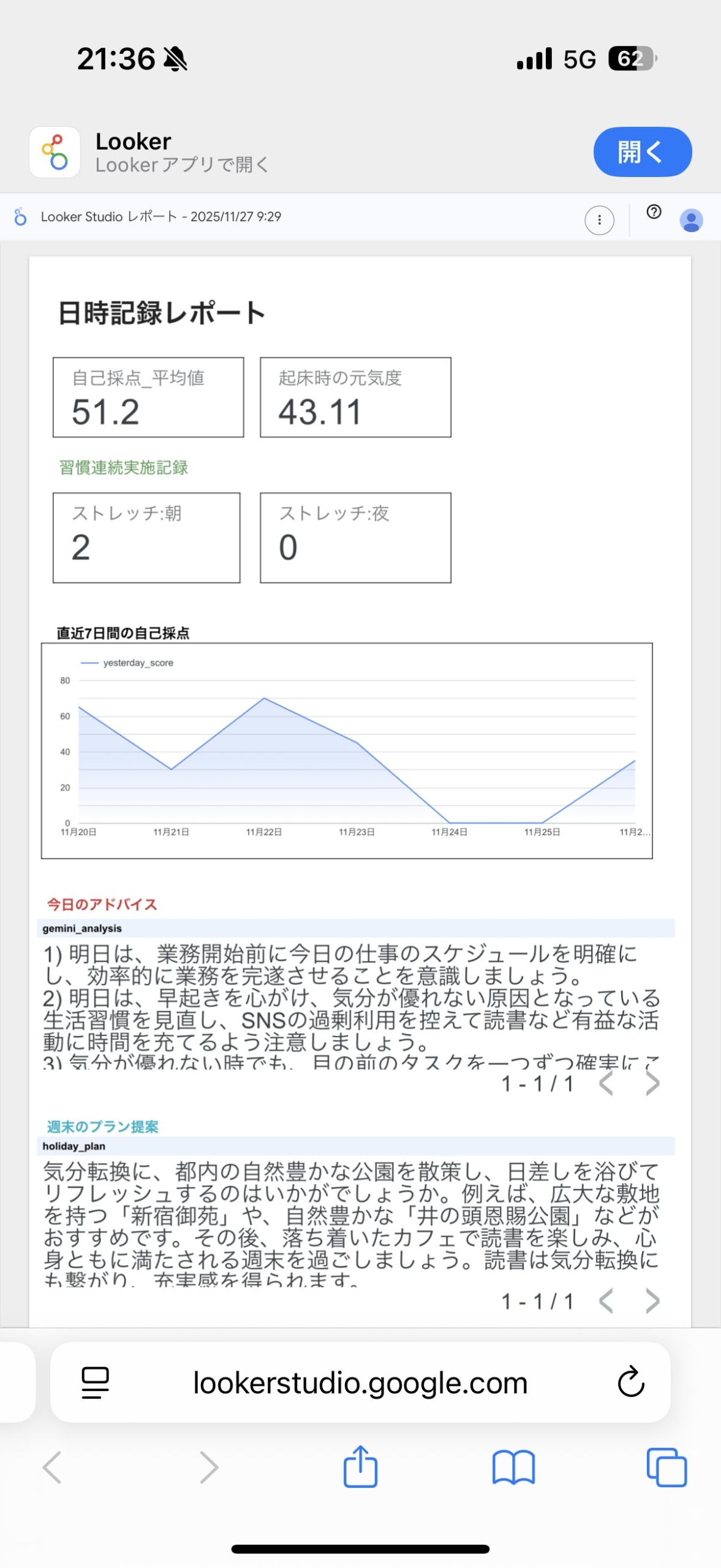
これにより、毎朝の通勤中にiPhoneで自分のコンディションとAIからのアドバイスをひと目で確認できる、「自分管理ダッシュボード」が完成しました。
いずれの項目も可視化できていなかったものなので、数字に表すと「目標を達成するために頑張ろう!」と背筋が伸びる思いです。
Geminiの週末プラン提案も平日を乗り越える励みになりそうです。
運用コストについて
現在の実装で運用を行うと、費用は毎月10円程度となっています。
GCPは無料枠も多いので、コストが抑えられて良いですね。
| リソース名 | 1ヶ月毎の料金 | 概要 |
| Cloud Run | 無料 | 月200万回の実行まで無料枠あり
今回の運用では月30回程度の実行で無料枠内 |
| BigQuery | 無料 | ストレージは月10GB、クエリは月1TBの無料枠あり
今回の運用では、どちらも1GBにも届かないため無料枠内 ※ 長期運用でデータが溜まりすぎると課金対象となる可能性があるため注意が必要 |
| Vertex AI | 約10円 | BigQuery内で呼び出しているGemini 2.5 flashモデルの使用料 日記が2,000文字程度、Geminiの出力が500文字程度で概算 |
まとめ
今回、Markdownの日記から、中長期的な記録を観測する「自分管理ダッシュボード」を構築することができました。
現時点では直近のデータのみで可視化することに注力していましたが、データが蓄積されることで長期的な自己理解へ役立てることもできそうです。
よりカスタマイズを加えていって、自分の生活を豊かにしていきたいです。
ここまで読んでいただきありがとうございました。
このブログから、「似たようなもの作れそう!」「もっといいもの作れる!」と刺激を受けてくれる方が1人でもいたら嬉しいです。
参考文献
- AI.generate_text 公式ドキュメント:https://docs.cloud.google.com/bigquery/docs/reference/standard-sql/bigqueryml-syntax-ai-generate-text
- Vertex AIのリモートモデル設定:https://www.google.com/url?q=https://docs.cloud.google.com/bigquery/docs/bigquery-ml-remote-model-tutorial?hl%3Dja&sa=D&source=docs&ust=1764251542333560&usg=AOvVaw1VGU0CbQMhPzOgbUBwL9hF







