
記事の要点
- マルチエージェント設計は、エージェントロール設計とオーケストレーション設計の両輪で考えることが重要。
- エージェントロールを切り分けるメリットは「自己バイアスの軽減」と「プロンプト最適化」にある。
- オーケストレーション手法である「Supervisor」と「Swarm」の特徴や違いを理解しよう。
はじめに
こんにちは、株式会社エスタイルのもっちーです。
近年、LLM(大規模言語モデル)の進化によって、AIエージェントが自律的にタスクを遂行する「マルチLLMエージェント構成」が注目を集めています。
単一のエージェントが一連の処理を担っていた時代から、複数のエージェントが役割を分担し、協調して課題を解決する時代へと進化してきました。
しかし実際にマルチLLMエージェントシステムを設計・運用しようとすると、次のような壁にぶつかることも多いのではないでしょうか。
- どんなエージェントロールを設定すべきか?
- 構成は何を考慮する必要があるか?
- 似たような構成が多く、違いがわかりにくい…
この記事では、私がLLMエージェント開発に携わる中で得た知見をもとに、マルチLLMエージェント設計の中核となる「エージェントロール設計」と「オーケストレーションパターン」について整理し、それぞれの特徴と設計指針をわかりやすく紹介します。
導入
最近、「LLMエージェント」という言葉を耳にする機会が増えました。
LLMエージェント(以下、エージェント)とは、LLMがさまざまな実行機能を備えることで、自律的に処理を行えるようになったものを指します。
エージェント化によって、LLMはプロンプト応答にとどまらず、ツールの呼び出しや外部システムとの連携、思考過程の展開など、より多機能で柔軟なタスク遂行が可能になりました。
しかし、それでもなお単一エージェントには限界があります。
複雑な業務や長期的な推論が必要なタスクでは、エージェントが一人で抱え込むには思考の幅が狭く、結果が安定しないことも少なくありません。
その解決策として注目されているのが、複数のエージェントが役割を分担し、協調してタスクを進める「マルチエージェント」というアプローチです。
用語整理
本題に入る前に、この記事を読むにあたって重要な3つの概念について整理します。
エージェントロール(Agent Role)
言葉の通り、エージェントが担う責務や機能のことを指します。
LLMにも「あなたは〇〇の専門家です」といったシステムプロンプトを与えることがありますよね。
概ねそれと同じイメージですが、エージェントの場合はそれに加えて、
どんなツールを使えるか、どんな情報を参照できるかといった設計もエージェントロールに含まれます。
ワークフロー(Workflow)
プログラミングでいうところの手続型(Procedural)に近い考え方です。
エージェントが自律的に判断して動くのに対し、ワークフローはあらかじめ決められた順番通りに処理を実行します。
ワークフローは再現性と安定性を担保することができます。実際に品質の良いアウトプットを出すにはエージェントとワークフローを組み合わせることが、とても重要です。
オーケストレーション(Orchestration)
これはマルチエージェントの文脈で頻繁に登場する概念です。
複数のエージェントが存在するとき、どのエージェントがどのタイミングで動き、
どのように協調するか、その連携を指揮・制御する仕組みがオーケストレーションです。
これら3つはいずれもマルチエージェント設計において重要な概念ですが、
本記事ではワークフローの詳細な組み合わせ方は割愛し、主にエージェントロール設計の考え方とオーケストレーションパターンについて解説していきます。
エージェントロール設計の考え方
責任範囲を切り分けることは、システムエンジニアリングの世界でも基本です。
マルチエージェントにおける「エージェントロールの切り分け」にも同様の利点がありますが、その目的は大きく異なります。
マルチエージェントでエージェントロール(以下、ロール)を切り分ける目的は、主に次の2つです。
- 自己バイアスの軽減
- プロンプトの最適化と焦点化
自己バイアスの軽減
ロール切り分けの本質的な狙いのひとつは、
LLMが自らの思考バイアスを検知・補正できる構造を持たせることにあります。
LLMは確率的生成モデルであるがゆえに、常に「自己一貫性バイアス(self-consistency bias)」を持ちます。[1]
つまり、一度導いた結論や仮定を正しいものとして強化し、再検証を行わないまま思考を進めてしまう傾向があるということです。
たとえば、LLMにコードを書かせた際に、実行するとエラーが出てしまうことがあります。
修正を依頼しても、同じライブラリ構成に固執したまま、的外れな修正を延々と繰り返してしまうケースがそれにあたります。
このケースは、そもそも提案されたライブラリが環境に適合していないことが原因である場合が多いのですが、LLMは最初に採用した前提(ライブラリ選定)を正しいと思い込み、発想の転換ができなくなるのです。
この課題を補う手法として有効なのが、複数ロールによる対話・評価構造です。
エージェント構成には「議論型(debate-based)」や「自己評価(self-reflection)」などもありますが、これらはまさに自己バイアス軽減を目的とした設計になります。
先の例でも確かに、「別ライブラリで同じロジックを提案できますか?」と人間が言うだけで、LLMは方向転換してくれますよね。
プロンプト最適化
次に、ロールを分けるもう一つの大きな理由がプロンプトの最適化です。
近年の研究では、入力文脈が長くなるほどLLMが“迷う”現象が報告されています。
| 研究 | 年 | 内容 |
| Lost in the Middle(Liu et al., 2023)[2] | 2023 | 長文の中間部分に置かれた重要情報をモデルが見落とす現象を報告。 |
| Same Task, More Tokens(Levy et al., 2024)[3] | 2024 | 入力を冗長化すると推論精度が有意に低下。特に3000トークン前後で急激な性能劣化を観測。 |
| Context Length Alone Hurts LLM Performance(Du et al., 2025)[4] | 2025 | 内容が正確でも、入力が長いだけで精度が下がる“注意散漫”現象を指摘。 |
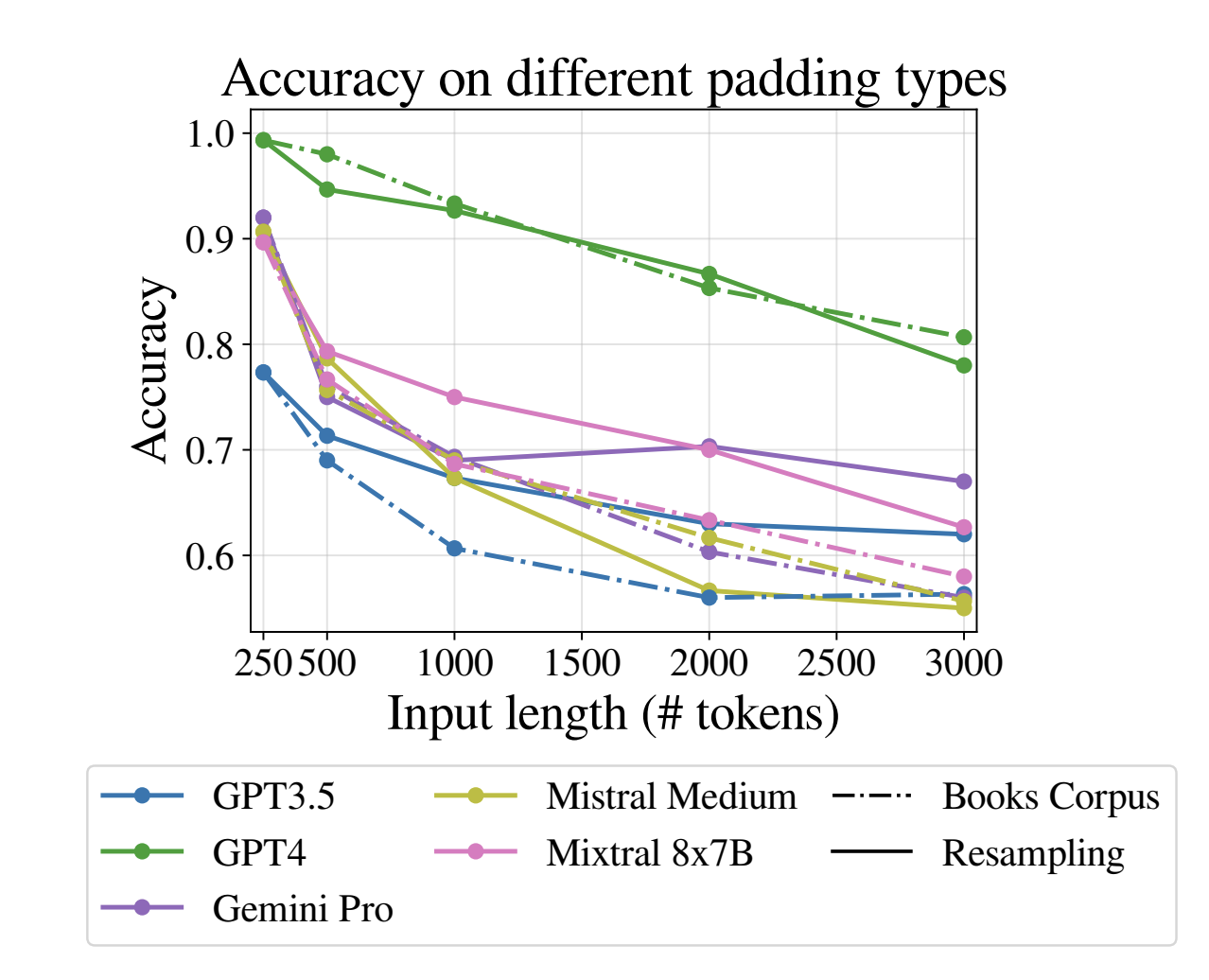
入力トークンと精度の相関を定量的に示している。[3] 例えばGPT-4はコンテキスト長が32Kトークンであるが、その10分の1である3Kトークン時点で20%も精度低下が見られる。
(引用: Levy et al., 2024 [arXiv:2402.14848](https://arxiv.org/abs/2402.14848))
Q&Aタスクや要約タスクではプロンプトを詰め込む設計は有用ですが、エージェントのように複数の判断を行うタスクでは、情報が増えるほど要点がぼやけ、出力が不安定になる傾向があります。
ロール切り分けはこの問題に対して非常に効果的で、
タスクごとに必要な情報だけを入力に集中させることで、プロンプトの“焦点距離”を最適化できます。
注意点
「では、できるだけ細かく分ければいいのでは?」と思うかもしれません。
しかし、ロールを増やしすぎると情報伝達の欠落やコンテキストの分断が起きやすくなります。(人が多い現場で情報伝達ミスが起きやすいのと非常に似たメカニズムです)
したがって、ロール切り分けは精度と一貫性のトレードオフであり、タスクの特性に応じて“どこまで分けるか”を見極める必要があります。
よく使われるロール例
| ロール | 概要 | 主な役割 |
| Planner | 全体計画を立てる | タスクの分解、戦略立案 |
| Critic | 結果を評価・指摘する | 精度検証、論理的整合性チェック |
| Judge | 複数結果から最適案を選択 | 最終意思決定、統合判断 |
オーケストレーションパターン紹介
マルチエージェントパターンは非常に多く研究されてきましたが、最近ようやく主流となるパターンが固まってきました。
多くのフレームワークで実装されつつあるオーケストレーションパターンは次の2つです。
- Supervisor型
- Swarm型
Supervisor型
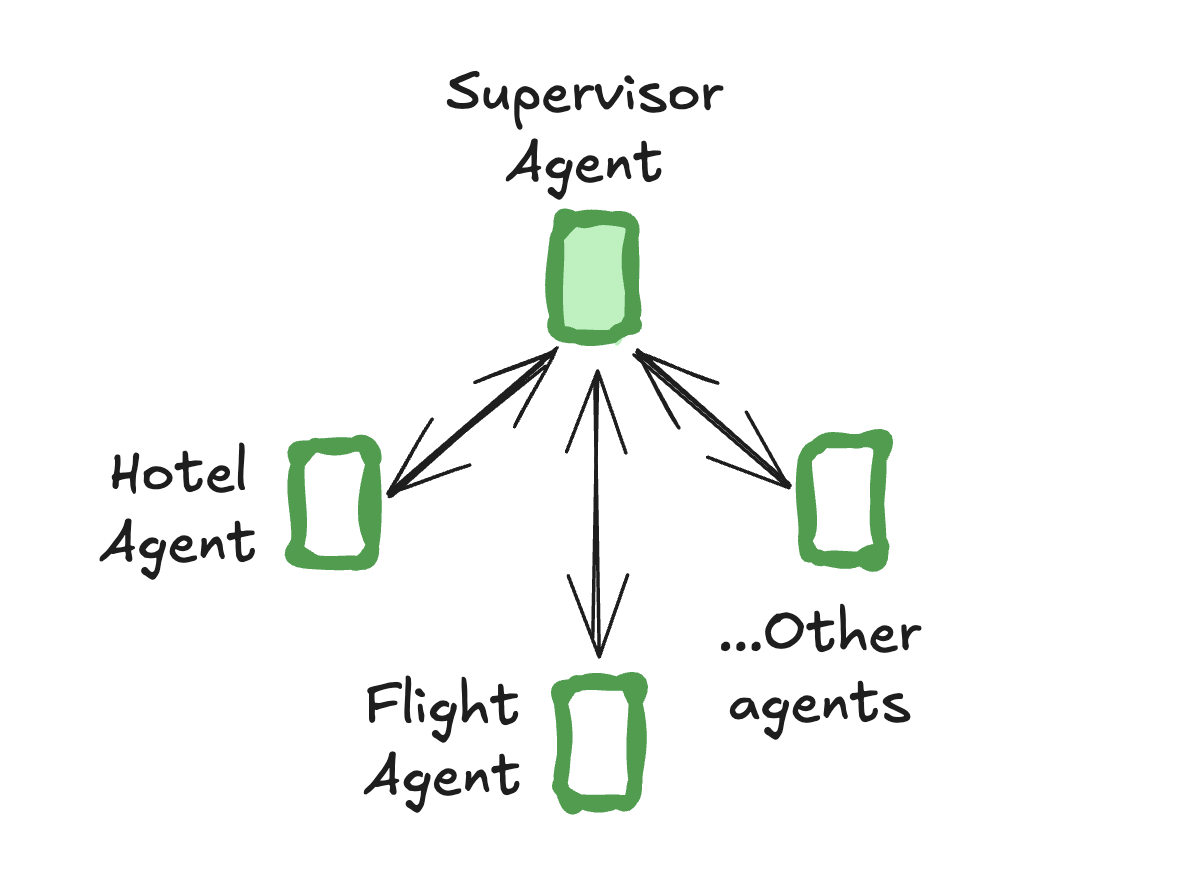
Supervisorのアーキテクチャ[6](引用: LangGraph公式ドキュメント)
Supervisorが各サブエージェントにタスクを割り振り、結果を回収・統合して最終回答を生成します。
特徴
- 構造:階層型(中央管理)
- 利点:動作管理が容易で、各エージェントの役割が明確
- 欠点:エージェント間のやりとりが多く、情報欠落(コミュニケーションロス)が発生しやすい
このアーキテクチャでは、必ずしもエージェント間でメッセージ履歴を共有する必要はありません。
ただし、多くの実装フレームワークでは履歴を共有する設計が採用されており、これによりタスクの一貫性を担保しています。(もちろん共有しない方がコンテキストを圧縮でき、良い場合もあります)
Swarm型
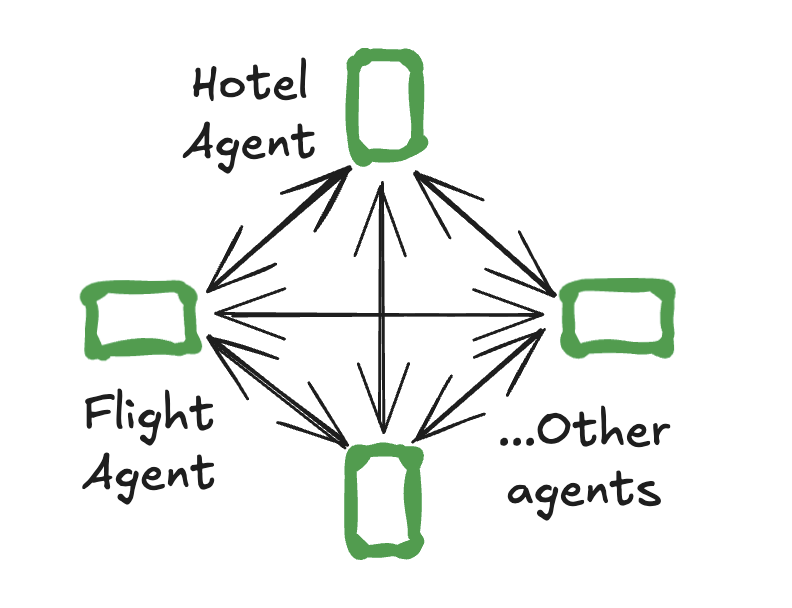
Swarmのアーキテクチャ[6](引用: LangGraph公式ドキュメント)
どのエージェントからでも他のエージェントへ直接ルーティングでき、中央への戻りは必須ではありません。
特徴
- 構造:分散型(フラット構造)
- 利点:中央集約が不要なため、トークン消費と応答時間が少ない
- 欠点:動作制御が難しく、構成を拡張しづらい
この構成ではエージェント間でメッセージ履歴を共有することが前提です。
全員が全体履歴を参照できるため、柔軟な協調が可能となります。
LangChainによる定量比較
LangChainが行った Mabench ベンチマークを確認すると、Swarm型とSupervisor型の違いがよく分かります。[5]
| アーキテクチャ | 精度(Mabench) | 備考 |
| Swarm | 約62% | 分散構造により通信ロスが少ない |
| Supervisor | 約47% | 中央集約による情報欠落が影響 |
Supervisor型では、各サブエージェントの出力が中央に集約されるため、エージェント間でやりとりする回数が多くなります。その分、情報欠落のリスクが高まるため、精度がSwarm型に比べて低いと考えられます。
さらに興味深いのは、Supervisor型でエージェント間のやりとりを減らす改良により、
精度が47% → 58%まで改善したという点です。
この改良版が現在では「Supervisorアーキテクチャの標準的実装」として広く採用されています。
まとめ
マルチエージェント設計は、単なる「エージェントを複数動かす」ことではなく、それぞれのロール設計とオーケストレーション構造をどう組み合わせるかが成否を分けます。
- ロール設計では、「自己バイアスの軽減」と「プロンプト焦点の最適化」が鍵になります。
役割を切り分けることで、エージェント間の相互評価や検証が可能となり、より安定した推論結果を得られます。 - オーケストレーション設計では、Supervisor型のような階層型構造と、Swarm型のような分散型構造のいずれを選ぶかが重要です。定量比較ではSwarm型の方が精度が良いですが、拡張性を考えるとSupervisor型を選択することを筆者はお勧めします。
参照文献
[1] Pride and Prejudice: LLM Amplifies Self-Bias in Self-Refinement (Xu et al., 2024)(https://arxiv.org/abs/2402.11436)
[2] Lost in the Middle: How Language Models Use Long Contexts (Liu et al., 2023) (https://arxiv.org/abs/2307.03172)
[3] Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models (Levy et al., 2024)(https://arxiv.org/abs/2402.14848)
[4] Context Length Alone Hurts LLM Performance Despite Perfect Retrieval (Du et al., 2025)(https://arxiv.org/abs/2510.05381)
[5] Benchmarking Multi-Agent Architectures (https://blog.langchain.com/benchmarking-multi-agent-architectures/)
[6] LangGraph公式ドキュメント(https://langchain-ai.github.io/langgraph/agents/multi-agent/)







