
記事の要点
- Databricks Genieは、SQLを書かずに分析の初速を大きく高められるツールである。
- 検証により、作品の人気の波やジャンルの盛衰を自然言語の指示だけで可視化できることが確認できた。
- AIは人の代わりに結論を出すのではなく、意思決定の材料をすばやく提示し、判断を助ける存在である。
はじめに
株式会社エスタイルのポッキーです。
本記事では、Databricks の AI アシスタント Genie を使い、Wikidata と Wikipedia Pageviews を組み合わせて「人気アニメのヒットの法則」を検証します。SQLなしの自然言語指示でどこまで集計・可視化できるか、どこから人の判断が必要かを実機で確かめ、Genie の強みと限界を整理します。
記事は「背景説明 → 環境準備 → 分析 → 学びと展望」の順で紹介します。
背景説明
Databricksとは?
Databricksは、データとAIのための統合プラットフォームで、主に以下の特長を持ちます。
- Lakehouse: DWHのような構造化データと、データレイクのような非構造化データを同一基盤で統合管理できるアーキテクチャ
- 統合環境: データの準備からAIモデルの開発、分析までをワンストップで実現
- ガバナンス: 組織全体で安全にデータを活用するための統制機能
本記事で扱うGenieは、この強力な基盤を背景に、誰でも自然言語でデータ分析を可能にする機能です。
Genieとは?
Databricks Genie は、自然言語で指示するとSQLを自動生成し、テーブル作成・集計・可視化までを支援してくれるAIアシスタントです。
ユーザーは「月別でグラフにして」「平均を出して」のように話しかけるだけで分析を進められます。データエンジニアだけでなく、ビジネスサイドの方にもデータに話しかける体験を提供します。
データの構成
今回の検証では、商用利用可能なオープンデータを利用しました。
| データソース | 内容 |
| Wikidata | 作品タイトル、ジャンル、制作会社、放送年などのメタ情報 |
| Wikipedia Pageviews | 各作品ページの閲覧数(日次) |
これらを組み合わせることで、「どんな属性のアニメが、いつ、どれくらい注目されたのか」をデータで明らかにできます。
分析環境の構築
まずDatabricks環境を整え、データを準備します。
前提条件:Databricks環境
本記事は、Unity Catalogが有効化済みであることを前提に進めます。Unity Catalogは、カタログ/スキーマ単位でデータを一元管理し、Genieが参照できる状態を整えるために不可欠です。詳細手順は割愛します。以下をご参照ください(公式/解説記事)。
- Unity Catalog の設定と管理(Databricks 公式)
- 日本語の解説記事(例:Qiita など)
構築ステップ(データ準備)
Genieに分析をしてもらうため、まず元となるデータを準備します。今回は、オープンなデータソースであるWikidataとWikipediaを使い、「アニメ作品の情報」と「その作品のWikipediaでの人気度」を組み合わせたデータセットを作成します。
※具体的な実装コードは、記事の最後にある Appendix(参考コード) に掲載しています。
Step0:Databricksワークスペースを理解する
Databricksの作業画面を簡単に紹介します。
Databricksでは、Google Colaboratory のように、コードとその実行結果(グラフやテーブルなど)を同じ画面で扱えるノートブックを使って作業します。PythonやSQLを1行ずつ実行しながら結果を確認できます。
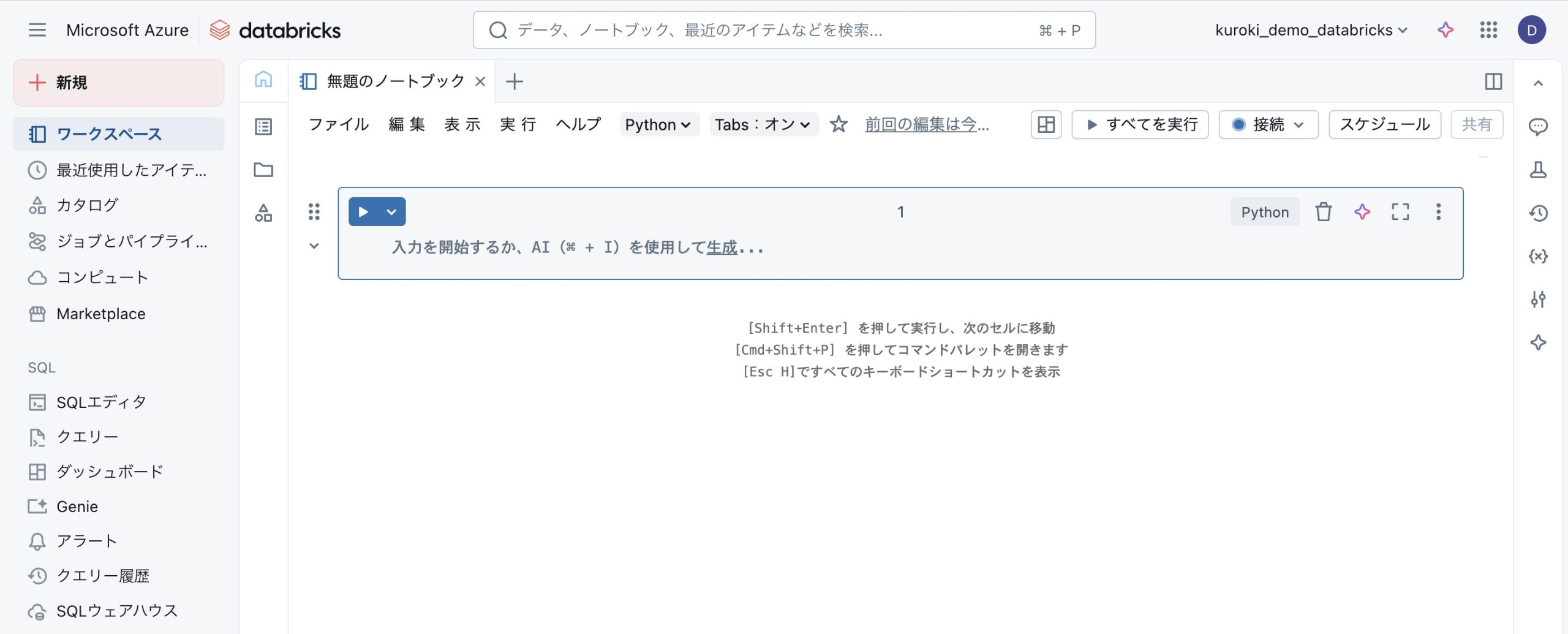
Step 1:テーブルの器を用意する(Schema Definition)
Databricks上に、「アニメの基本情報」と「日々のWikipedia閲覧数」を入れるテーブルを2つ作成します。
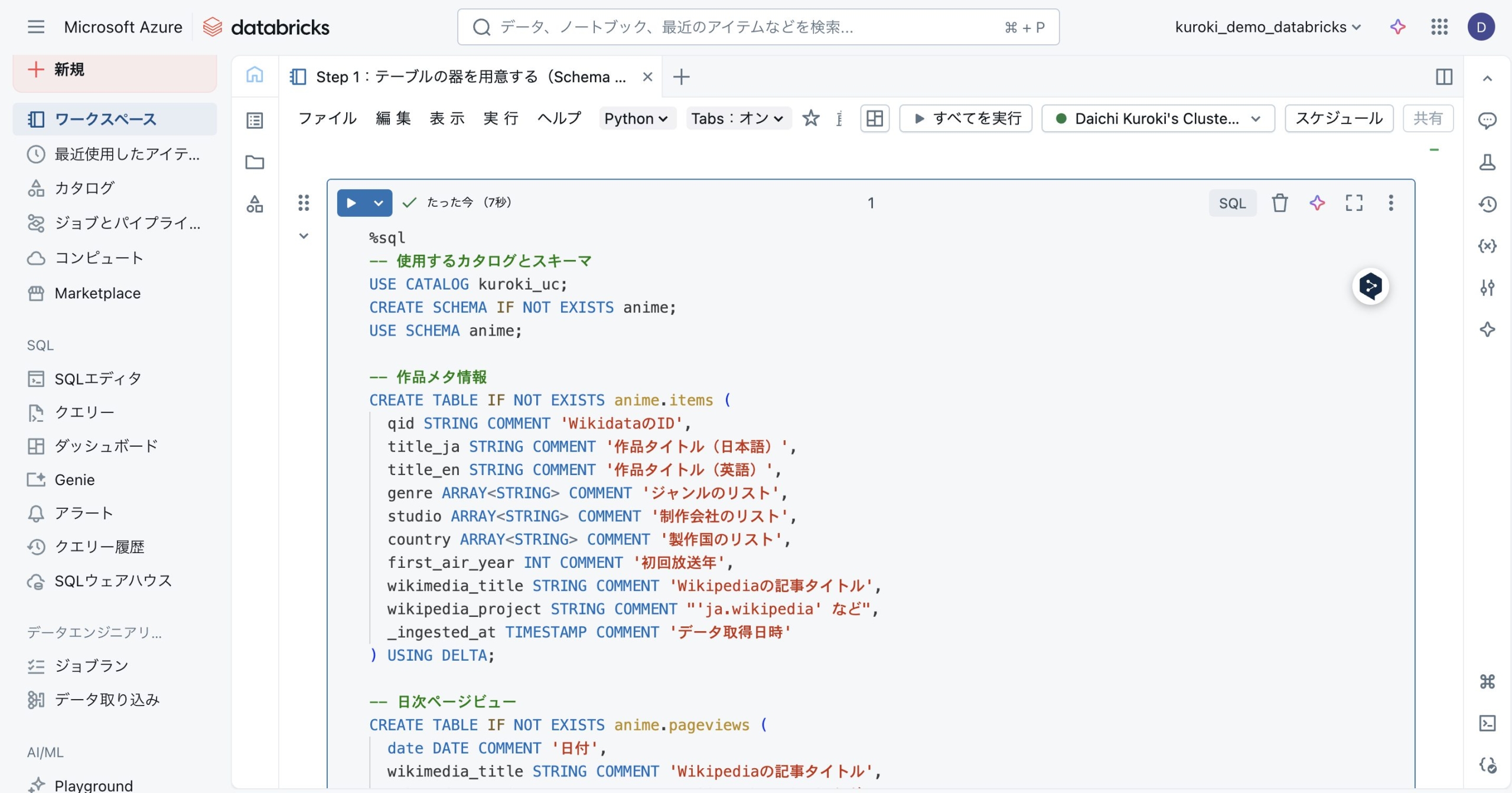
Step 2:Wikidataから作品メタ情報を取得
Wikidataからアニメ作品のタイトル、制作会社、放送年といったメタデータを取得し、1つ目のテーブルに格納します。
Step 3:Wikipedia Pageviewsを取得
各アニメ作品のWikipediaページが日々どれくらい見られているか、API経由で閲覧数を取得し、2つ目のテーブルに格納します。
3-1. テーブルの受け皿を用意
3-2. 直近365日の PV を取得 → 一時ビューに格納
3-3. UPSERT(重複を避けて Delta へ投入)
Step 4:分析用ビューを作成
最後に、これら2つのテーブルを組み合わせ、「作品ごとの直近30日間の平均閲覧数」などがすぐに見られる分析用のビューを作成します。

以上でデータの準備が整いました。下図はテーブル/ビューの関係をまとめたものです。以降の分析では、主に v_anime_pv30(直近30日)と v_anime_pv_monthly_last12(直近12か月)をGenieから参照します。

分析ステップ(AIとの対話)
ここからは、Genieに話しかけるだけで分析していきます。
【調査1】アニメ人気の波をデータで追う
特定作品の人気の変化を見てみます。
【質問】
「鬼滅の刃」のWikipedia月間閲覧数の推移を、折れ線グラフで表示して
【Genieの回答】
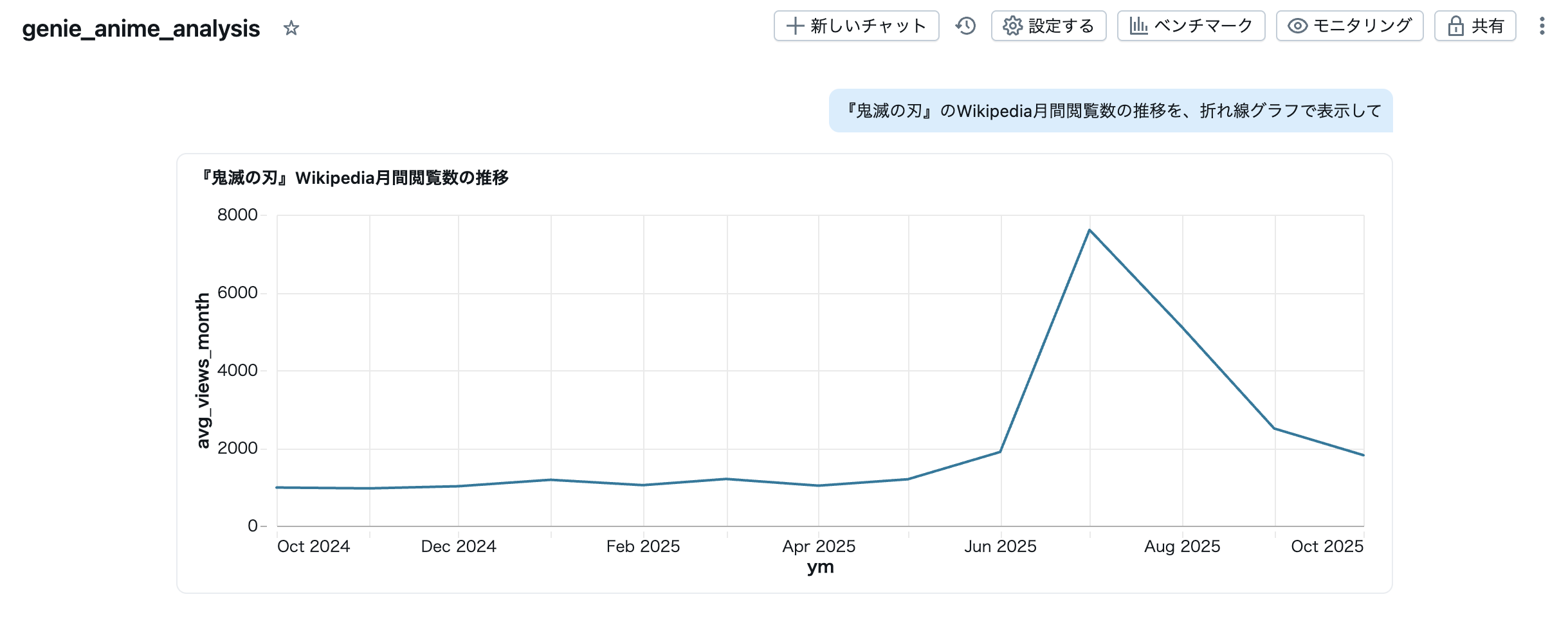
【考察】
- 閲覧数の時間推移の可視化をワンショットで完了しました。
- グラフから2025年7月前後で閲覧数が急増していることが分かります。
- ただし、スパイクの理由付け(背景特定)は外部情報との突き合わせが必要で、AI単体では難しいです(今回は映画公開が急増の理由)。
【調査2】時代ごとのジャンルの盛衰
続いて、2000年代・2010年代・2020年代で「どんなジャンルが多く制作されたのか」を聞いてみます。
【質問】
2000年代、2010年年代、2020年代で、それぞれ最も多く制作されたアニメのジャンルトップ5を教えて(縦軸count、横軸decadeでグラフにして)
【Genieの回答】
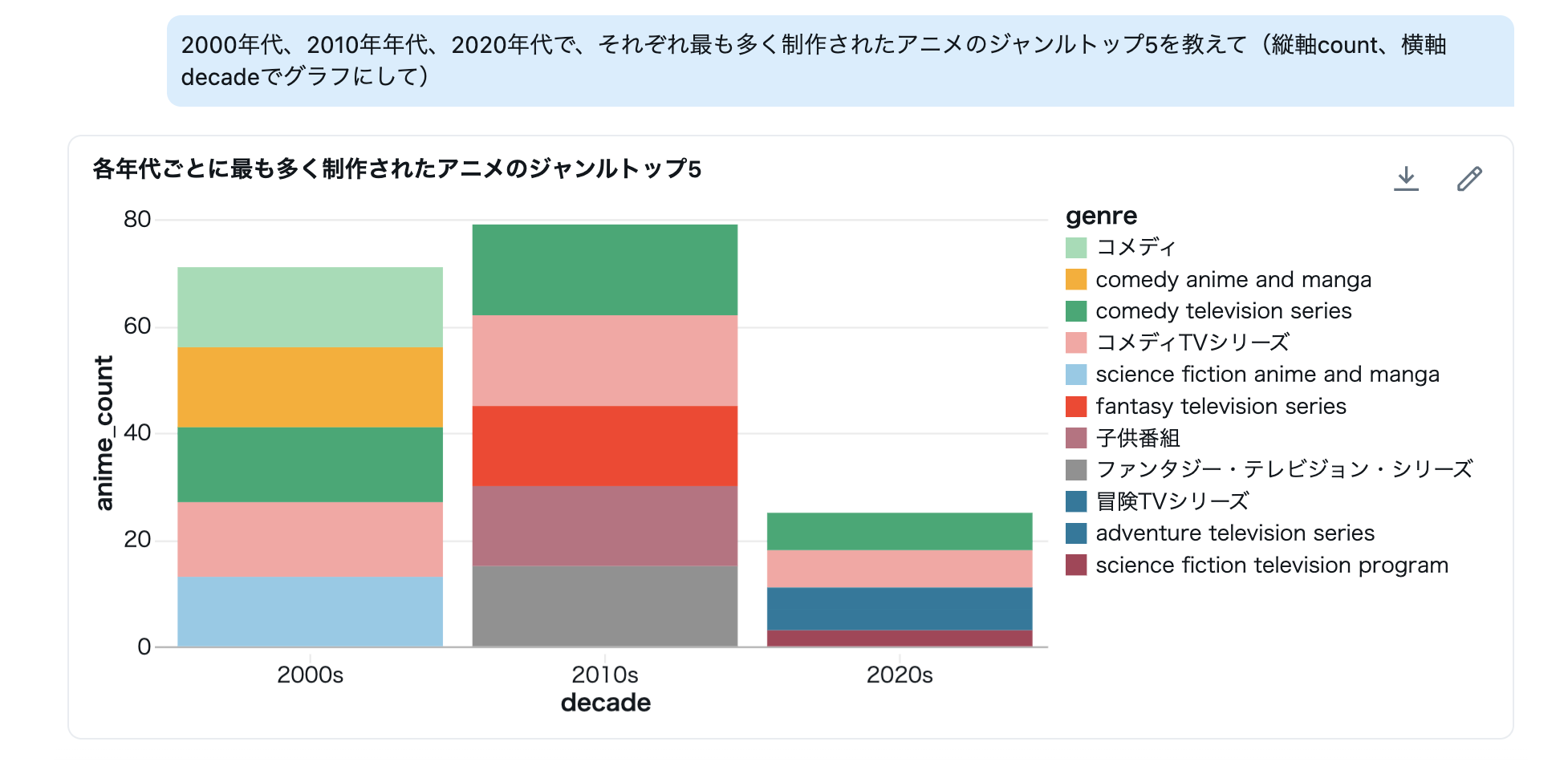
【考察】
- 年代区分→ジャンル配列の展開→集計→ランキングという多段処理を自然言語で実行できます。
- 集計軸の定義(年代境界・表記ゆれの統一)によって結果が変わるため、前処理とルールの明示が重要になります。
- 可視化は傾向の提示まで。因果の説明や解釈は人間の役割になります。
【調査3】ジャンルの表記ゆれ改善に挑戦
次に試したのは、データ整形に関するタスクです。
【質問】
genreカラムに『アクション』『アクションアニメ』『Action anime and manga』など表記ゆれがあります。意味的に同じものをまとめて分析できるように、似たジャンルを統合してください。
【Genieの回答】

考察】
- Genie は意味的な類似語を自動でまとめることはできません。ただし、決められたルールに沿ってデータをまとめることは可能です。
- 例えば、同じ意味のジャンル名を「代表ラベル」に統一したい場合、人が対応表を作り、そのルールに従ってデータをまとめることができます。
- 実務では「ジャンルの一覧を抽出 → 似た表記をまとめる表(マッピング)作成 → その表を使ってデータを統一」という流れで進められます。
【調査4】AIは未来を予測できるか?
最後に、過去の傾向から「次に流行るジャンル」を予測できるか質問してみました。
【質問】
次に流行りそうなジャンルを予測して
【Genieの回答】

【考察】
- Genie は未来を予測することはできません。
- ただし、過去のデータを分析して「どのジャンルが伸びているか」「どこで注目が高まったか」を見つけることができます。
- 効果的に使うには、人が仮説を立て、条件(期間・対象など)を具体的に設定することが重要です。
まとめ/今後の展望
今回の検証を通して、2025年10月時点での Genie の「強み」と「限界」が明確になりました。
Genie は、SQL を書かずに自然言語でデータを集計・可視化できるという点で、分析の初動を劇的に速くするツールです。
一方で、「曖昧な指示の解釈」や「未来の予測」といった創造的な思考はまだ不得手です。
しかし、これは弱点ではなく、AI と人間の役割が補完関係にあることを示しているとも言えます。
| 項目 | Genieの得意領域 | Genieの苦手領域 |
| 集計・可視化 | 自然言語→SQL→グラフ化を高速に実行 | 非構造化データの分析は不可
巨大データや複雑なJOINは時間がかかる場合あり |
| データ整形 | 明示的なルールに基づく正確な統合(再現性重視) | 意味的な同一性の自動判定、クラスタリングの自動化は不可 |
| 推論・洞察 | 過去データから傾向を要約・説明 | 未来予測や創造的な仮説立案は対象外 |
触ってみて一番感じたのは、Genieはなんでもできる分析者ではなく、人の仮説を加速させてくれる相棒だということです。思いついたアイデアをその場で検証できて、「これって本当にそうなの?」をすぐ確かめられます。そんなスピード感が、データ分析をもっと楽しく、身近なものにしてくれます。
今後の期待:
- 可視化結果の自動解釈・要約
- 自然言語による機械学習の操作(学習・評価・予測の一連の支援)
- 構造化データとテキスト/レビューなど非構造化データの横断分析
こうした進化が進めば、もっと多くの人がAIと会話しながらデータで考える世界が当たり前になっていくと思います。これまで専門家だけが扱っていた分析の世界が、誰でも直感的に触れられるものになるでしょう。
たとえば、AIがグラフを見てポイントを教えてくれたり、質問するだけで機械学習の予測を試せたり、顧客の口コミと数値データを組み合わせて分析できたりと、データに対するハードルがぐっと下がっていくはずです。
AIを通してデータと対話しながら、新しい発見を生み出す時代。その始まりを、すでに少しずつ感じ始めています。
Appendix(参考コード)
この記事で使用したデータ準備のコードです。
Step 1:テーブルの器を用意する(Schema Definition)
-- 使用するカタログとスキーマ
USE CATALOG test_uc;
CREATE SCHEMA IF NOT EXISTS anime;
USE SCHEMA anime;
-- 作品メタ情報
CREATE TABLE IF NOT EXISTS anime.items (
qid STRING COMMENT 'WikidataのID',
title_ja STRING COMMENT '作品タイトル(日本語)',
title_en STRING COMMENT '作品タイトル(英語)',
genre ARRAY COMMENT 'ジャンルのリスト',
studio ARRAY COMMENT '制作会社のリスト',
country ARRAY COMMENT '製作国のリスト',
first_air_year INT COMMENT '初回放送年',
wikimedia_title STRING COMMENT 'Wikipediaの記事タイトル',
wikipedia_project STRING COMMENT "'ja.wikipedia' など",
_ingested_at TIMESTAMP COMMENT 'データ取得日時'
) USING DELTA;
-- 日次ページビュー
CREATE TABLE IF NOT EXISTS anime.pageviews (
date DATE COMMENT '日付',
wikimedia_title STRING COMMENT 'Wikipediaの記事タイトル',
wikipedia_project STRING COMMENT "'ja.wikipedia' など",
views BIGINT COMMENT '閲覧数',
_ingested_at TIMESTAMP COMMENT 'データ取得日時'
) USING DELTA
PARTITIONED BY (date);
Step 2:Wikidataから作品メタ情報を取得
# %python
"""
Wikidata → Spark DataFrame → Delta(anime.items)
- 対象:アニメシリーズ(Q581714) or そのジャンルを持つ作品
- 条件:ja.wikipedia に記事があるもの
- 出力:test_uc.anime.items(Delta)
"""
import re
import requests
from typing import Any, Dict, List, Optional
from pyspark.sql import Row, functions as F, types as T, Window
# ============================================================
# 0) 定数・環境設定
# ============================================================
# ★必ず自社の連絡先に置き換えてください(Wikimediaポリシー順守)
USER_AGENT = "<クライアント名>/<バージョン> (<連絡先情報>)"
CATALOG = "test_uc"
SCHEMA = "anime"
OUTPUT_TABLE = f"{SCHEMA}.items"
ENDPOINT = "https://query.wikidata.org/sparql"
SPARQL = """
SELECT DISTINCT
?item
(SAMPLE(?jaLabel) AS ?jaLabel)
(SAMPLE(?enLabel) AS ?enLabel)
(GROUP_CONCAT(DISTINCT ?genreLabel; separator="|") AS ?genreLabels)
(GROUP_CONCAT(DISTINCT ?studioLabel; separator="|") AS ?studioLabels)
(GROUP_CONCAT(DISTINCT ?countryLabel; separator="|") AS ?countryLabels)
(MIN(?pubDate) AS ?pubFirstDate)
?article ?wiki ?title
WHERE {
# instance/subclass of: animated series
{ ?item wdt:P31/wdt:P279* wd:Q581714 . }
UNION
# genre includes: animated series
{ ?item wdt:P136/wdt:P279* wd:Q581714 . }
OPTIONAL { ?item wdt:P136 ?genre . ?genre rdfs:label ?genreLabel FILTER (lang(?genreLabel) IN ("ja","en")) }
OPTIONAL { ?item wdt:P272 ?studio . ?studio rdfs:label ?studioLabel FILTER (lang(?studioLabel) IN ("ja","en")) }
OPTIONAL { ?item wdt:P495 ?country . ?country rdfs:label ?countryLabel FILTER (lang(?countryLabel) IN ("ja","en")) }
OPTIONAL { ?item wdt:P577 ?pubDate . }
# sitelink(日本語版のみ)
?article schema:about ?item ;
schema:isPartOf ?wiki ;
schema:name ?title .
FILTER (?wiki IN (<https://ja.wikipedia.org/>))
OPTIONAL { ?item rdfs:label ?jaLabel FILTER (lang(?jaLabel) = "ja") }
OPTIONAL { ?item rdfs:label ?enLabel FILTER (lang(?enLabel) = "en") }
}
GROUP BY ?item ?article ?wiki ?title
LIMIT 5000
"""
spark.sql(f"USE CATALOG {CATALOG}")
spark.sql(f"USE SCHEMA {SCHEMA}")
# ============================================================
# 1) ユーティリティ
# ============================================================
def jval(binding: Dict[str, Any], key: str) -> Optional[str]:
"""SPARQLの1件(binding)から値を安全に取得。"""
v = binding.get(key)
return v.get("value") if isinstance(v, dict) and "value" in v else None
def split_pipe_unique(pipe_str: Optional[str]) -> List[str]:
"""'A|B|B|C' → ['A','B','C'](順序維持・重複排除)"""
if not pipe_str:
return []
out, seen = [], set()
for token in (p.strip() for p in pipe_str.split("|")):
if token and token not in seen:
seen.add(token)
out.append(token)
return out
def parse_first_year(iso_date: Optional[str]) -> Optional[int]:
"""'YYYY-MM-DD' などから年だけ抽出(不正なら None)。"""
if not iso_date:
return None
m = re.match(r"^(\d{4})", iso_date)
return int(m.group(1)) if m else None
def qid_from_uri(uri: Optional[str]) -> Optional[str]:
"""'http://www.wikidata.org/entity/Q123' → 'Q123'"""
if not uri:
return None
return uri.rsplit("/", 1)[-1] if uri.startswith("http") else uri
# ============================================================
# 2) SPARQL 実行
# ============================================================
session = requests.Session()
resp = session.get(
ENDPOINT,
params={"query": SPARQL, "format": "json"},
headers={"User-Agent": USER_AGENT},
timeout=60,
)
resp.raise_for_status()
bindings = resp.json()["results"]["bindings"]
# ============================================================
# 3) JSON → Row 化
# ============================================================
rows: List[Row] = []
for b in bindings:
qid = qid_from_uri(jval(b, "item"))
# 日本語版のみを対象(英語版は除外)
project = "ja.wikipedia"
title = jval(b, "title") or "" # ja の記事タイトル
# ラベルと属性
title_ja = jval(b, "jaLabel")
title_en = jval(b, "enLabel")
genres = split_pipe_unique(jval(b, "genreLabels"))
studios = split_pipe_unique(jval(b, "studioLabels"))
countries = split_pipe_unique(jval(b, "countryLabels"))
first_air_year = parse_first_year(jval(b, "pubFirstDate"))
rows.append(Row(
qid=qid,
title_ja=title_ja,
title_en=title_en,
genre=genres,
studio=studios,
country=countries,
first_air_year=first_air_year,
wikimedia_title=title, # APIに渡す元タイトル(ja)
wikipedia_project=project, # 'ja.wikipedia' 固定
))
# ============================================================
# 4) DataFrame 化 & 重複除去・付加情報
# ============================================================
schema = T.StructType([
T.StructField("qid", T.StringType()),
T.StructField("title_ja", T.StringType()),
T.StructField("title_en", T.StringType()),
T.StructField("genre", T.ArrayType(T.StringType())),
T.StructField("studio", T.ArrayType(T.StringType())),
T.StructField("country", T.ArrayType(T.StringType())),
T.StructField("first_air_year", T.IntegerType()),
T.StructField("wikimedia_title", T.StringType()),
T.StructField("wikipedia_project", T.StringType()),
])
df = spark.createDataFrame(rows, schema)
# 同一 qid の多重行が返る可能性に備え、代表1行へ(ja→enの順で安定)
w = Window.partitionBy("qid").orderBy(
F.coalesce(F.col("title_ja"), F.col("title_en")).asc_nulls_last()
)
df_dedup = (
df.withColumn("rn", F.row_number().over(w))
.filter("rn = 1")
.drop("rn")
)
# 監査用タイムスタンプを付与
df_final = df_dedup.withColumn("_ingested_at", F.current_timestamp())
# ============================================================
# 5) Delta へ保存
# ============================================================
(df_final
.write
.format("delta")
.mode("overwrite") # 既存構造を置き換え
.option("overwriteSchema", "true")
.saveAsTable(OUTPUT_TABLE))
Step 3:Wikipedia Pageviewsを取得
3-1. テーブルの受け皿を用意
-- %sql
USE CATALOG test_uc;
CREATE SCHEMA IF NOT EXISTS anime;
USE SCHEMA anime;
CREATE TABLE IF NOT EXISTS anime.items(
qid STRING,
title_ja STRING,
title_en STRING,
genre ARRAY,
studio ARRAY,
first_air_year INT,
country ARRAY,
wikimedia_title STRING,
wikipedia_project STRING,
_ingested_at TIMESTAMP
)
USING DELTA
TBLPROPERTIES (
delta.enableChangeDataFeed = true
);
CREATE TABLE IF NOT EXISTS anime.pageviews (
date DATE,
wikimedia_title STRING,
wikipedia_project STRING,
views BIGINT,
_ingested_at TIMESTAMP
) USING DELTA
PARTITIONED BY (date);
3-2. 直近365日の PV を取得 → 一時ビューに格納
# %python
"""
Wikipedia Pageviews(ja)を 直近365日 分取得し、一時ビュー 'pv_stage_last365' に格納
- 取得対象: test_uc.anime.items の (wikimedia_title, wikipedia_project='ja.wikipedia')
- API: /metrics/pageviews/per-article/{project}.org/all-access/user/{title}/daily/{start}/{end}
"""
import time
import urllib.parse
import requests
from datetime import date, timedelta
from typing import List
from pyspark.sql import Row, functions as F, types as T
# =========================
# 0) 定数・環境
# =========================
spark.sql("USE CATALOG test_uc")
spark.sql("USE SCHEMA anime")
# ★Wikimediaポリシー順守: 自社連絡先を必ず設定
USER_AGENT = "<クライアント名>/<バージョン> (<連絡先情報>)"
BASE_URL = "https://wikimedia.org/api/rest_v1/metrics/pageviews/per-article"
PAUSE_EVERY = 20 # 何リクエストごとにスリープするか
SLEEP_SEC = 1.5 # 429回避。必要に応じて増やす
BATCH_LIMIT = 3000
end = date.today()
start = end - timedelta(days=365)
start_str, end_str = start.strftime("%Y%m%d"), end.strftime("%Y%m%d")
# =========================
# 1) 取得対象の抽出(ja のみ)
# =========================
targets: List[Row] = (
spark.table("anime.items")
.select("wikimedia_title", "wikipedia_project")
.where("wikipedia_project = 'ja.wikipedia' AND wikimedia_title IS NOT NULL")
.distinct()
.limit(BATCH_LIMIT)
.collect()
)
print("TARGET COUNT:", len(targets))
# =========================
# 2) API コール & バッファ
# =========================
rows, ok, not_found, errors = [], 0, 0, 0
for i, r in enumerate(targets, start=1):
title = r["wikimedia_title"].replace(" ", "_")
article = urllib.parse.quote(title, safe="_")
project_org = r["wikipedia_project"] + ".org" # 'ja.wikipedia.org'
url = f"{BASE_URL}/{project_org}/all-access/user/{article}/daily/{start_str}/{end_str}"
try:
resp = requests.get(url, headers={"User-Agent": USER_AGENT}, timeout=30)
if resp.status_code == 404:
not_found += 1
continue
resp.raise_for_status()
for it in resp.json().get("items", []):
rows.append(Row(
date=it["timestamp"][:8],
wikimedia_title=r["wikimedia_title"],
wikipedia_project=r["wikipedia_project"],
views=int(it["views"])
))
ok += 1
except Exception as e:
errors += 1
print("ERR:", r["wikimedia_title"], e)
if i % PAUSE_EVERY == 0:
time.sleep(SLEEP_SEC)
print(f"RESULT: ok={ok}, not_found={not_found}, errors={errors}, rows={len(rows)}")
# =========================
# 3) Spark DataFrame へ → 一時ビュー
# =========================
schema = T.StructType([
T.StructField("date", T.StringType()),
T.StructField("wikimedia_title", T.StringType()),
T.StructField("wikipedia_project", T.StringType()),
T.StructField("views", T.LongType()),
])
pv_df = spark.createDataFrame(rows, schema) if rows else spark.createDataFrame([], schema)
pv_df = (
pv_df
.withColumn("date", F.to_date("date", "yyyyMMdd"))
.withColumn("_ingested_at", F.current_timestamp())
)
pv_df.createOrReplaceTempView("pv_stage_last365")
3-3. UPSERT(重複を避けて Delta へ投入)
-- %sql
USE CATALOG test_uc;
USE SCHEMA anime;
MERGE INTO anime.pageviews AS t
USING (
SELECT DISTINCT date, wikimedia_title, wikipedia_project, views, _ingested_at
FROM pv_stage_last365
) AS s
ON t.date = s.date
AND t.wikimedia_title = s.wikimedia_title
AND t.wikipedia_project = s.wikipedia_project
WHEN MATCHED THEN UPDATE SET
t.views = s.views,
t._ingested_at = s._ingested_at
WHEN NOT MATCHED THEN INSERT * ;Step 4:分析用ビューを作成
-- %sql
-- 直近30日平均PV
CREATE OR REPLACE VIEW anime.v_anime_pv30 AS
SELECT i.qid,
COALESCE(i.title_ja, i.title_en) AS title,
i.genre, i.studio, i.first_air_year,
AVG(p.views) AS avg_views_30d
FROM anime.items i
JOIN anime.pageviews p
ON p.wikimedia_title = i.wikimedia_title
AND p.wikipedia_project = i.wikipedia_project
WHERE p.date >= date_sub(current_date(), 30)
GROUP BY ALL;
-- 直近12か月の月次平均PV(可視化用)
CREATE OR REPLACE VIEW anime.v_anime_pv_monthly_last12 AS
SELECT COALESCE(i.title_ja, i.title_en) AS title,
DATE_TRUNC('month', p.date) AS ym,
AVG(p.views) AS avg_views_month,
i.genre, i.studio, i.first_air_year
FROM anime.items i
JOIN anime.pageviews p
ON p.wikimedia_title = i.wikimedia_title
AND p.wikipedia_project = i.wikipedia_project
WHERE p.date >= add_months(current_date(), -12)
GROUP BY ALL;
参考文献
- Wikidata (総合案内ページ):https://www.wikidata.org/wiki/Help:Contents/ja
- Wikimedia REST API(Pageviews):https://wikimedia.org/api/rest_v1/
- Databricks Genie ドキュメント:https://docs.databricks.com/aws/ja/genie
- Unity Catalog:設定と管理(公式):https://docs.databricks.com/aws/ja/data-governance/unity-catalog
- 【Databricks】Unity Catalogセットアップガイド:https://qiita.com/taka_yayoi/items/62da2ab414d08a74c69c







